编者按:本文来自微信公众号 半导体行业观察(ID:icbank),创业邦经授权发布。
编者按
早前,韩银河老师等人撰写了一篇题为《The Big Chip: Challenge, Model and Architecture》的文章。按照文章摘要所说,随着摩尔定律的终结,通过晶体管微缩实现高性能芯片变得越来越困难。为了提高性能,增加芯片面积以集成更多晶体管已成为必不可少的手段。然而,由于掩膜版面积、成本和制造良率等限制,芯片面积无法持续增大,遇到了所谓的“面积墙”难题。
在本文中,我们(指代本文作者等人)对“面积墙”进行了详细分析,并提出了一种实用的解决方案——大芯片(Big Chip),作为一种新颖的芯片形式以提高性能。我们介绍了一种评估大芯片的性能模型并讨论了其架构。
最后,我们得出了大芯片未来的发展趋势。
1、摘要
在深度神经网络 (DNN) 和科学计算日益普及的推动下,云和边缘平台的利用率正在快速增长[1], [2]。进行人工智能训练所需的算力呈指数级增长,每 3.4 个月翻一番。自 2012 年以来,该指标已增加了30多万倍。然而,这些算法的计算强度相当大,仍然是其实际部署的重大障碍。因此,人们越来越需要提高芯片性能以满足更高计算能力的需求。芯片的性能与以下三个因素有关:
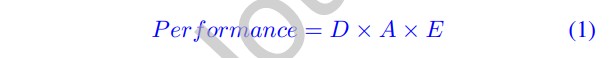
D代表晶体管密度,一般与制造工艺和器件机制有关。A代表芯片面积,与集成规模有关。E代表架构因素,反映每个晶体管的性能,通常由芯片的结构决定。我们将上述公式称为芯片性能的DAE模型。因此,当使用相同的芯片架构时,改善晶体管尺寸和面积是增强芯片性能的两个关键方法。
集成电路 (IC) 的制造工艺在历史上一直与摩尔定律同步发展。目前,我们已经达到5nm工艺的量产阶段,3nm工艺正在稳步推进。工艺节点的每一次突破都带来了性能的提高和功耗的降低。然而,随着摩尔定律[2]和登纳德缩放比例[3]接近极限,增加集成到单个芯片中的晶体管数量变得越来越具有挑战性且成本高昂[4]。
随着晶体管尺寸的缩小变得越来越困难,集成更多功能单元的一种可行方法是增加芯片面积。然而,扩大单芯片面积时可能出现的一个重要障碍就是我们所说的“面积墙”。面积墙是指由于制造技术和成本的限制引申出的对单个芯片的面积限制。芯片的制造依赖于光刻,芯片面积受到光刻孔径的限制[5]。由于掩膜版的尺寸和光学器件的物理特性,单个芯片最大曝光区面积限制为858mm(26mm * 33mm)。要增加最大曝光区面积,光刻系统必须取得重大进展,而这从成本角度来看是一项挑战。此外,成本是增加芯片面积的另一个挑战。在更先进的工艺节点中,单位芯片面积的成本会增加[6]。最后,对于大面积芯片来说,良率也是一个重大挑战,这将导致制造缺陷的发生频率更高,导致晶圆良率下降[7]。
为了设计一种突破面积墙限制的芯片,我们提出了一种新颖的芯片形式,称为大芯片。“大芯片”一词是指面积大于目前最先进光刻机最大曝光区面积的芯片。这种类型的芯片通常还具有大量晶体管,并使用半导体制造技术来实现。大芯片有两个特点:首先,大芯片面积大,打破了步进式光刻机的面积限制,将大量晶体管集成到一个芯片中,可以超过当前制造技术下单片芯片上集成的晶体管数量。其次,大芯片由多个功能裸芯组成,并使用几种新兴的半导体制造技术将预制裸芯集成到大芯片中。Cerebras利用平面制造技术实现晶圆级大芯片,面积达46,225毫米。芯粒集成[8]、[9]、[10]、[11]、[12]、[13]、[14]、[15]、[16]也是一项有前途的技术,它将多个芯粒组合在单个封装内的中介层或基板上。AMD和Nvidia分别于2019年[12]和2020年[17]推出了基于多芯粒架构的高性能处理器设计。由于芯片面积较大,芯片性能得以大幅提升。
尽管构建大芯片受到广泛关注,但该领域的综合分析论文却稀缺且迫切需要。本文对大芯片进行了详细分析。首先,我们详细分析了面积墙,考虑到物理限制、良率和成本。在此分析的基础上,我们进一步介绍了可用于实现大芯片的潜在技术。其次,我们提出了一个性能模型来指导大芯片的设计和评估。最后,我们给出了基于芯粒技术构建大芯片的架构实现方式以及未来的发展趋势。
2. 挑战:芯片的面积墙
高性能计算系统需要更多的计算能力来支持许多领域的计算密集型工作。更多的计算能力需要更多的集成晶体管,这可以通过更大的芯片面积和更密集的硅结构来实现。然而,由于晶圆成本、良率和更复杂的设计规则问题,硅结构密度增长最近已经放缓。因此,实现更高计算能力的最佳方法是集成更大的芯片。然而,传统的单片集成存在面积墙问题,阻碍了芯片面积的增长。幸运的是,多芯片集成技术可以显著削弱面积墙的影响。本节我们将详细分析造成面积瓶颈的三个原因。
2.1
光刻曝光区面积限制
在现代光刻系统[5]、[18]、[19]中,掩膜版在倾斜入射光下曝光,来自掩膜版的携带信息的反射光经过一组光学器件,最终落在晶圆表面,如图1所示。晶圆上的曝光图像实际上是掩膜版上图像的缩小,给定放大倍数 MAG,晶圆上曝光的图像尺寸为掩膜版上尺寸的1/MAG。衡量表面上可以收集多少光的重要指标称为数值孔径,其定义为光锥张角一半的正弦值。掩膜版和晶圆表面的数值孔径为 , ,其中如图 1 所示。这两个数值孔径的关系式为[5]:
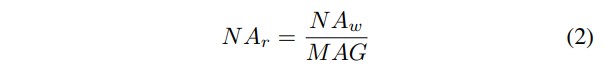
有两种选择可以增加晶圆曝光区面积,设计更小的光学器件MAG,并增加掩膜版面积。然而,这两种方案在目前的行业中都很难实现。
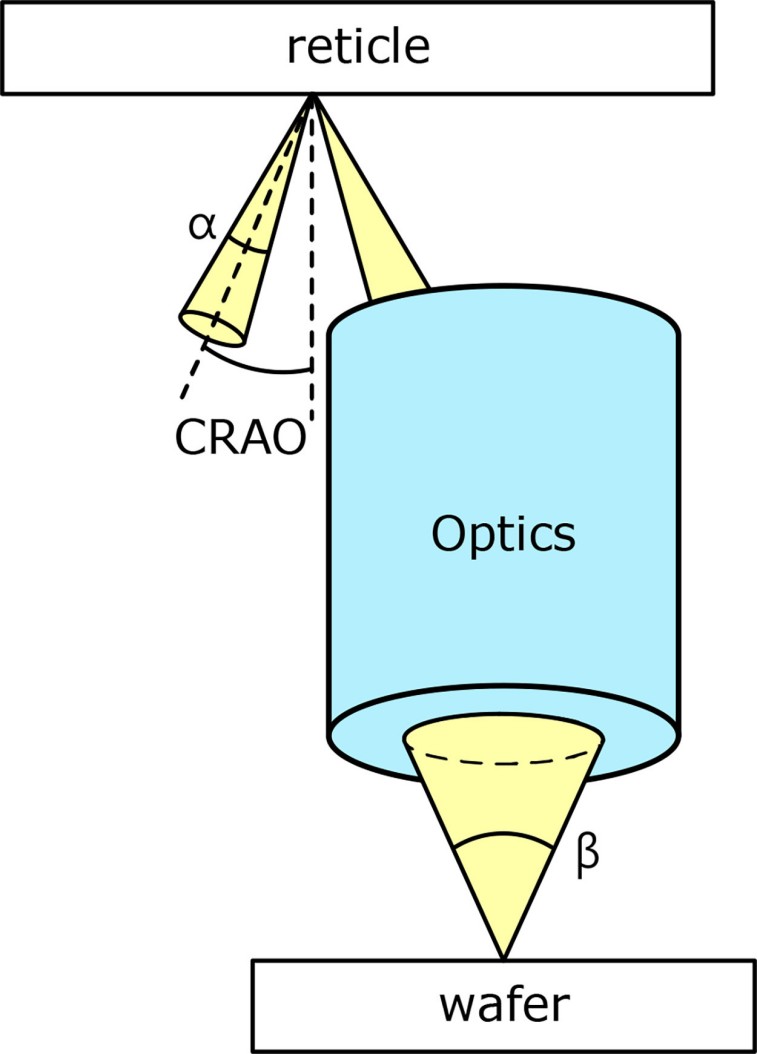
图 1. 光刻系统演示。
根据瑞利准则[20],更先进的工艺节点要求增加 。这使得光学器件无法设计成较小的 MAG,因为根据公式2, 会随着增大而增大。因此, 会变大,并迫使目标处的主光线角(CRAO,如图 1 所示)变大,这样入射光锥和反射光锥就不会重叠。然而,较大的 CRAO 会降低图像质量和掩膜效率。因此,目前大多数先进的光刻系统都采用 MAG = 4 的光学器件,而更先进的工艺节点可能需要更大的 MAG。
假设光罩的宽度和长度分别为和 ,则曝光尺寸可用下式表示:
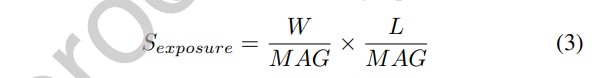
目前市场上最大的光罩尺寸为 6",剔除制造余量后的尺寸为 104mm×132mm。由于目前先进的光刻系统的 MAG = 4,因此目前的最大曝光尺寸为 26mm×33mm=858 mm²。需要强调的是,我们的上述分析主要针对硅基芯片制造,并没有考虑 TFT(薄膜晶体管)制造等工艺。
2.2
良率限制
一直以来,工业界都在寻求一个精确的模型来预测芯片的良率以指导生产[21]。此外,良率模型对于探索可能的集成水平以指导芯片设计也很重要。人们提出了几种在不同假设条件下预测良品率的模型。泊松良率模型假定缺陷分布均匀且随机,这往往会低估大型芯片的良率。Seeds模型引入了指数分布模拟芯片之间的缺陷密度变化。负二项式模型利用缺陷密度和缺陷聚类现象来确定良率,这种模型被广泛使用。下式是预测单片芯片良率的负二项模型,其中 是取决于工艺节点的缺陷密度, 是缺陷聚类参数[21]:
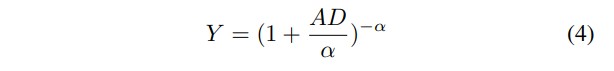
在此基础上,我们提出了通用多芯片系统的良率模型。一般的多芯粒系统可抽象为几个部分,每个部分 又分为 个相同的芯粒。中每个芯粒的面积为 ,其中 是 的总关键面积(关键一词是指排除芯片间模块),是芯片到芯片面积与关键面积之比。由具有缺陷密度和聚类参数 、的加工节点制造,其良率可按单片情况预测。我们建议,多芯粒系统的良率由所有部件的最小良率决定。注意,集成过程也会引入潜在的故障,因此集成良率也应计入系统良率。假设键合芯粒的成功率为 ,为芯片 i(由 组成)的良率,定义为芯粒 i 的实际良率与目标良率之比:
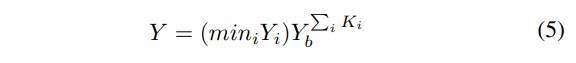
单片集成在实现较大的芯片面积时,尤其是在工艺节点先进的情况下,存在良率低的问题。我们认为,在相同的良率目标下,多芯粒集成能比单片集成实现更大的芯片总面积。在此,我们考虑了只有一个部件 P 的 K-chiplet 系统,并将其与单片芯片进行比较。K-chiplet 系统良率的计算公式为
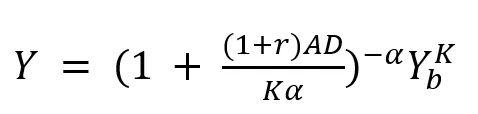
通过良率模型的反函数,我们可以分别建立单片系统和 K-chiplet 系统所能达到的最大关键面积模型如下:
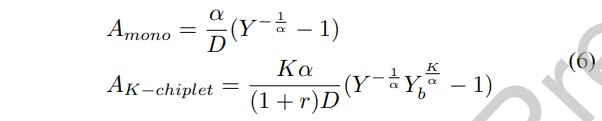
由于多芯粒系统的良率肯定小于键合良率,因此 Y 存在一个内部约束条件,即Y<YbK。等式 6 可以很好地解释。对于 AK-chiplet,第一个乘积项表明,更大的关键面积可以用更多的芯粒(更大的 K)来制造,但这受到芯粒与芯粒模块比例的阻碍。第二个乘积项是反映集成过程开销的系数,表明集成开销阻碍了多芯粒系统的扩展。在极端情况下,如果键合良品率为 100%,则该系数将变为 1。实际上,第二项小于 1,并且随着 K 的增大而变小,这表明在集成更多芯粒时集成开销更高。
图 2 显示了在给定良率限制(横轴)下,使用单片和芯粒集成技术可实现的最大关键面积(纵轴)。在相同的成品率限制下,使用更多芯粒进行集成通常能获得更大的关键面积。此外,多芯粒系统还能轻松突破单片芯片的物理面积限制(虚线标记)。
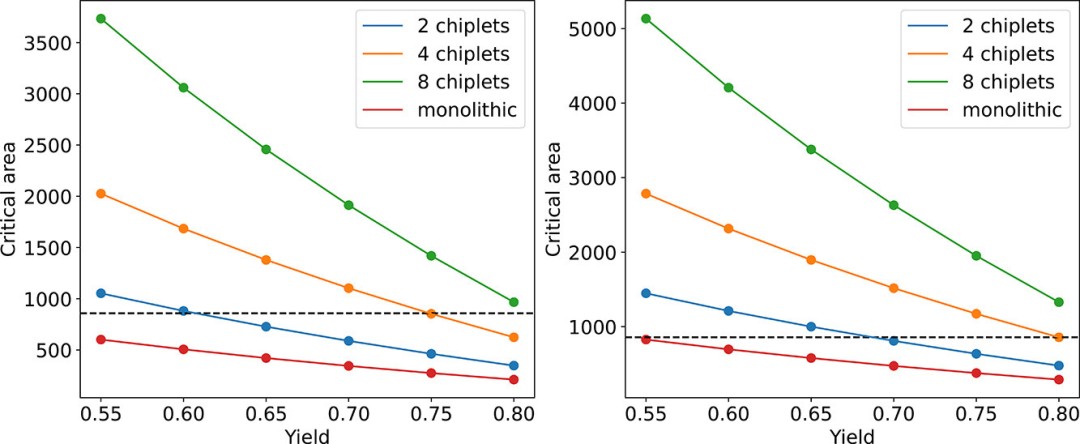
图 2. 在良率限制下可制造的最大关键面积(平方毫米)。左图和右图分别显示 5 纳米和 14 纳米工艺。水平虚线表示 858 平方毫米的物理单片芯片面积上限。
2.3
成本限制
制造成本可根据集成系统各部分的良率和原料成本估算。对于单片芯片,成本可以简单地用裸片良率和裸片成本估算,其中良率用于摊销失效裸片的成本。对于多芯粒系统,如文献[6]、[7]、[22]、[23]所述,成本计入多个组成部件和集成过程。我们对单片系统和多芯粒系统的制造成本建模如下:
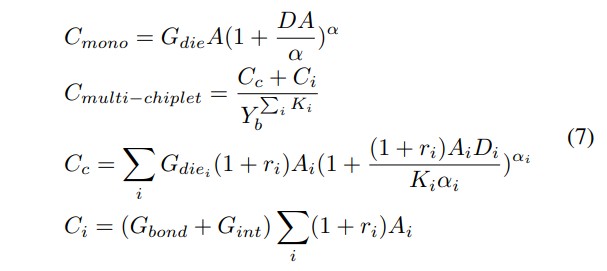
其中Gdie、Gint、分别为单位面积芯片和插层的原始成本。是将单位面积芯片键合到集成电路上的成本。
根据这一成本模型,我们再次比较单片系统和 K-chiplet系统的成本效率,如图 2 所示。我们将晶体管数量建模为晶体管密度乘以关键面积,并在图 3 中绘制出每个晶体管的成本。我们还在图 4 中绘制了系统成本的对比图。
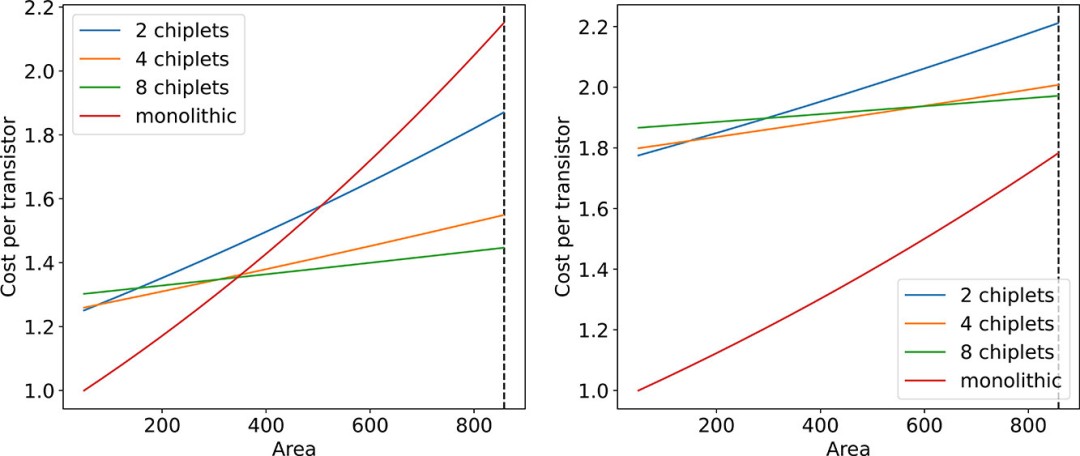
图 3. 采用 5 纳米(左)和 14 纳米(右)工艺节点的不同关键面积(平方毫米)时每个晶体管的成本。成本已归一化为图中最小单片芯片的成本。
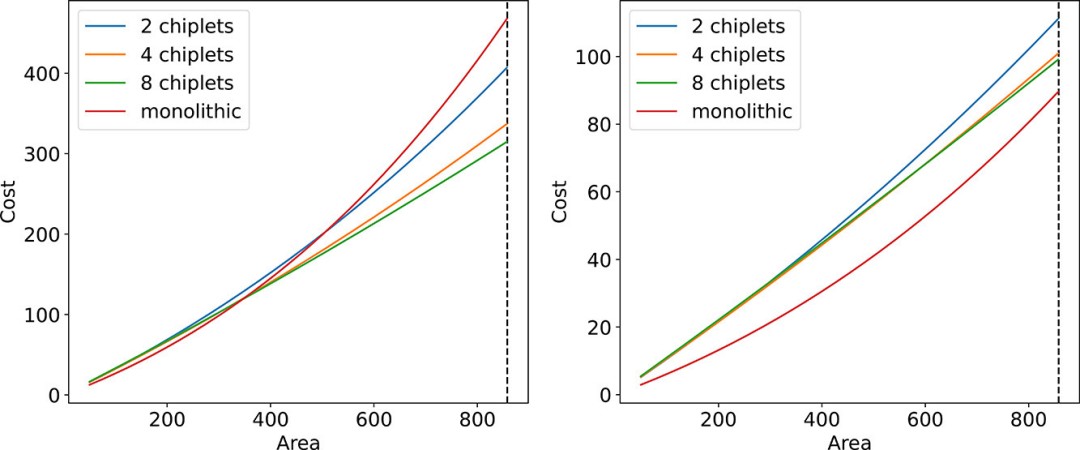
图 4. 采用 5 纳米(左)和 14 纳米(右)工艺节点的不同关键面积(平方毫米)时的系统成本(任意单位)。
对于成熟的工艺节点(见图 3 和图 4 中的 14 纳米),单片系统的单位晶体管成本和系统成本均低于多芯粒系统。然而,对于新节点和先进节点,多芯粒系统在关键面积较大的情况下成本更低。请注意,在图中,我们没有显示超过 858 平方毫米(虚线)的关键面积,因为它只能通过芯粒集成来实现。同时,芯粒越多的系统成本曲线增长越平滑,这表明在实现足够大的关键面积时,芯粒越多的系统成本优势越明显。
3. 技术:打破面积墙
大芯片由超过万亿个晶体管和数千平方毫米的面积(超过一个掩膜版)组成,目前可采用两种方法实现。第一种方法是芯粒集成,即在中介层或基板上将多个芯粒组合在单个封装中。2018 年,AMD 提出了 EPYC 处理器,利用 MCM(多芯片模块)技术集成了四个相同的芯粒[24]。华为也提出了基于芯片集成的服务器 SoC 系列[25]。通过台积电 CoWoS技术,鲲鹏 920 SoC 系列集成了多个不同功能的芯粒。第二种方法是晶圆级集成(WSI),即用整个硅晶圆构建超大型集成电路。1980 年,Trilogy System 为 IBM 大型机进行了晶圆级集成的早期尝试[26]。这种集成将芯片间的通信放在晶圆上,从而降低了芯片间通信的延迟和功耗。然而,良率和光刻问题导致 Trilogy System 的晶圆级集成失败[26]。Cerebras System 于 2019 年实现了晶圆级引擎-1(WSE-1)[27],并于 2021 年实现了晶圆级引擎-2(WSE-2)[28]。这两种方法都能大大提高芯片的性能。然而,大芯片的设计和实现也面临着一些挑战,包括制造和封装、设计成本和 IP 重用、良率和散热。在下面的章节中,我们将深入探讨这些挑战以及芯片集成和晶圆级集成所提供的解决方案。
制造和封装。在大芯片中,确保裸片封装具有高性能和可靠的裸片间互连非常重要。在标准制造中,划线是将芯片与相邻芯片分开的区域。为了实现晶圆级集成,需要在划片线上铺设大量导线,以实现晶圆上的芯片互连。例如,Cerebras System WSE-1[27]使用了最新提出的台积电 InFO_SoW 封装技术[29],如图 5(a)所示,在刻线上添加导线,实现了网状互连,其线路密度和带宽密度是 MCM 的 2 倍。芯片设计不需要在刻线上添加导线来连接芯片,而是在有机基板或硅插层[24]、[30]上实现裸片之间的通信,从而提供更灵活、更多样化的芯片布局选择。封装是晶圆级集成的另一个挑战。在考虑大规模晶圆和 PCB 的封装时,有必要减轻晶圆和 PCB 因受热而产生的不同热膨胀的影响,从而提高封装的可靠性[27]。此外,在封装过程中还必须考虑大型晶圆和 PCB 之间相互作用造成的影响,如机械应力。为了提高封装性能,一些缓冲应力的元件(如连接器)被用来缓解这些问题[27]。然而,额外引入的连接器增加了封装的难度。需要确保晶片、连接器和印刷电路板之间的凸点精确对齐。目前,还没有一种可靠的封装工具能保证这种对齐要求,因此需要重新开发一种新的定制封装工具[27]。如图 5(b)[4]所示,片式集成提供了多种成熟且经过验证的 2D/2.5D/3D 封装技术,这些片式封装的可靠性也已在一些研究中得到证实[31],[32]。
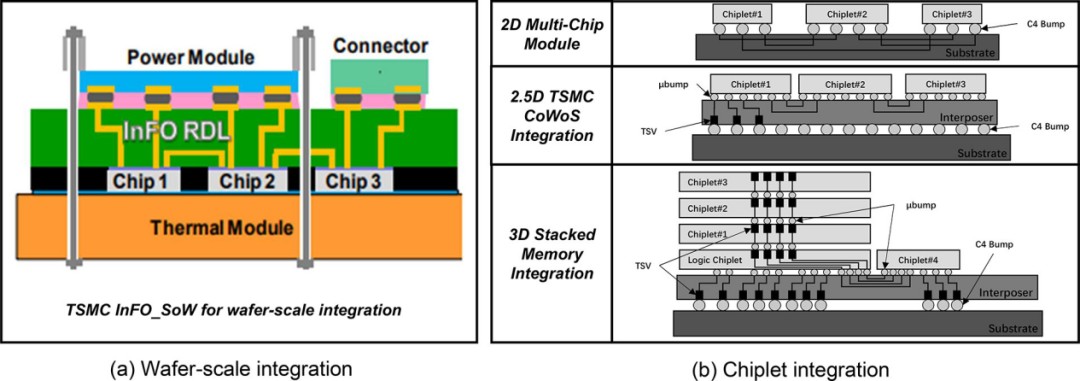
图 5. 芯片级集成与晶圆级集成的制造和封装比较[4], [29]。
设计成本和 IP 重用。在构建大芯片时,需要考虑设计时间和相关成本,其中 IP 重用是帮助降低设计成本的常用方法。由于晶圆级集成是在同一晶圆上实现所有芯片,因此晶圆上的每个芯片都是通过相同的工艺实现的[27]。这导致系统设计存在两个缺陷。首先,晶圆级集成降低了使用成熟且先进的工艺的可能性。其次,晶圆级集成的特点是系统紧密,晶圆上的芯片很难作为功能组件重复使用[33]。芯片 IP 重用方案如图 6 所示。系统应用被分解成许多基本功能裸芯,然后进行逻辑组合和物理集成。与晶圆级集成相比,芯粒封装技术支持对异构工艺制造的芯片进行集成。它允许以高性能为目标的重要工艺单元通过先进工艺来实现,而其他单元(例如IO)可以通过成熟工艺来实现,从而提高计算能力并最小化成本[34]。此外,所实现的芯粒作为预组件或IP,可以在下一代设计中重复使用,这显着缩短了设计时间并降低了设计成本[35]。因此,chiplet集成通过IP复用带来了降低设计成本的突出优势。
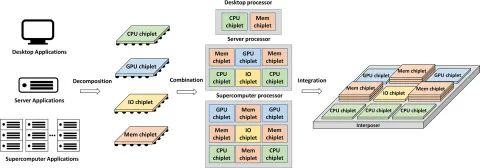
图6 芯粒IP 复用表
良率。基于多芯粒系统的大芯片的整体良率是一个更值得关注的因素。Chiplet集成和晶圆级集成分别引入了Known Good Die(KGD)[36]方法和冗余设计[27]来提高整体良率。由于器件和环境因素的影响,很难保证晶圆上的每个芯片都是好的,这意味着对于晶圆级集成来说,不可避免地会导致晶圆上的芯片出现缺陷。此外,由于一些晶圆级集成设计在划片中添加了互连线,因此划片区域中出现的缺陷也会损害良率。为了解决良率挑战,Cerebras 提出了冗余设计,其中包括 1.5%额外的核心[27]。作为类似的晶圆级集成设计,Trilogy System的芯片引入了2倍冗余设计[26]。这种冗余设计允许禁用有缺陷的芯片,然后用冗余芯片替换,冗余芯片与其他良好芯片的链接将在结构上重建,从而避免由于有缺陷的芯片而导致片上网络和通信的性能下降。然而,冗余设计和重新连接增加了设计开销,并且需要设计者和代工厂之间紧密的协同设计。相反,芯粒技术有利于提高整体良率。芯粒有两个方面的良率提升。第一个是通过减小单个芯片尺寸来提高良率[37]。基于芯粒技术,可以用小芯片集成大芯片。随着芯片尺寸变小,良率也会提高。提高良率的第二个层次是使用已知良好芯片(KGD)[36]进行封装。芯粒技术不是从晶圆上切割最大的正方形,而是从晶圆上切割单个芯片,只允许封装通过老化测试的单个芯片,从而提高良率。
散热。随着大芯片中集成的晶体管数量越来越多,芯片的功耗猛增,大芯片的功耗可以大得惊人。因此,散热就成为一个关键问题。在晶圆级集成中,WSE [27]开发了冷平面和定制连接器来解决散热和热效应。热量通过水和芯片之间的接触而被带走。在当前的芯粒集成中,引入散热器来散热[30]。与带有大型水冷系统的晶圆级集成相比,带有小型散热器的芯粒集成的散热解决方案在移动和边缘应用中更加灵活。
4. 模型:评估大芯片
4.1
性能需求模型
大芯片系统的巨大规模带来了新的挑战,例如对内部芯粒的片外访问和长距离通信的限制。高度的可定制性以及广泛的集成技术和架构使得很难确定特定市场的最佳设计[38]。在这种情况下,需要一个通用性能模型来深入了解大芯片设计的关键方面,并为架构改进提供指导,包括集成技术选择、并行性、互连和内存层次结构设计、片外带宽等
我们提出了一个性能模型来表征不同规模区域的性能瓶颈。尽管并不完美,但该模型提供了对关键方面的见解,可以提高给定设计的性能上限。我们首先解释如何推断该模型,重点关注数据通信和并行性,这是决定系统性能的关键因素。然后,我们确定了提高不同区域峰值性能的方法,并说明了模型在某些方法下如何变化。
4.2
性能模型外推
我们研究大芯片系统扩展时的性能变化。为了兼顾数据通信和并行性等方面,我们选择面积(A)作为表示系统规模变化的变量。造成整个系统处理延迟的主要因素有三个,即计算、片外访问和芯片间(或内核间)通信。这三个部分的延迟可简单计算为:

其中,CA 指计算能力,BWoff-chip指芯片外带宽,BWintra-chip指芯片间或内核间带宽。其中,αoff-chip和 αintra-chip是归一化的数据移动量,分别表示每次计算(以 B/op 为单位)从片外存储器和芯片(或内核)之间移动的数据量。
现在,我们需要弄清楚CA、BWs和A之间的关系。随着系统规模的扩大,采用特定设计的大芯片的计算能力呈线性增长。其关系可表示为:
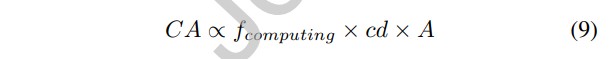
cd指的是计算元件的密度,fcomputing指的是计算频率。在某种设计中,可以通过将芯片(或内核)中的计算元件数量按其面积划分来估算cd。
芯片外访问带宽与芯片周长成正比,因为 I/O 布置在芯片边缘。如果我们将 I/O 密度视为特定设计,那么芯片外带宽与面积之间的关系可估算为:
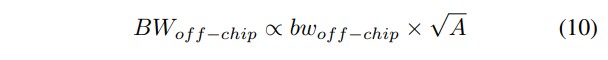
其中,bωof f-chip表示沿芯片边缘的芯片外带宽密度,单位为 GB ps/mm。它也可以表示为 I/O 密度与数据传输频率的乘积。
当涉及芯片间或内核间通信延迟,有两个基本假设。第一个假设是总线上的数据传输是同时进行的。在这种假设下,片内通信延迟应该是所有总线延迟中的最大值:
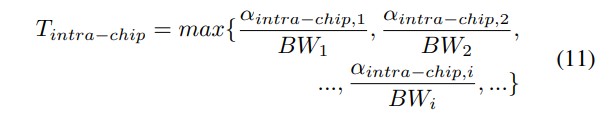
第二个假设是,大芯片系统的扩展主要取决于相同基线设计的重复性,基线设计可以是芯片或内核的设计。那么,每个基线设计的带宽(即等式 11 中的BWi)可视为常数。因此,芯片内通信延迟可表示为:

然后,我们推断总延迟与这三个决定性部分的关系。在此,我们引入了另一个与上述第一个假设类似的新假设,即计算、芯片外访问和芯片内通信同时运行。那么我们有:

由于性能与延迟成反比,我们可以得出:
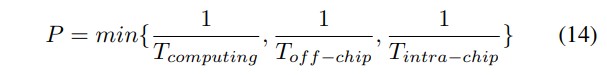
这是在估算延迟时的一个极端假设,还有另一个极端假设,即这三个操作是完全相继进行的。那么总延迟等于所有三部分延迟的总和。实际情况介于这两个极端之间。即使在这种极端情况下,我们也可以假设每个区域都有一个部分主导总延迟,那么表达式就与公式 14 相同。将等式 9、10 和 12 代入等式 14,我们就得到了作为芯片面积函数的最终性能模型:

这三个部分的分别是与面积成正比、与面积的平方根成正比和随面积变化而不变。在其他参数取值不同的情况下,性能模型的趋势应该有三种可能,如图 7 所示。在图 7(a)所示的平衡模式中,性能模型被划分为 3 个区域。在芯片面积较小的第一个区域,计算能力不足是性能的关键瓶颈。随着系统规模的扩大,片外访问阻碍了并行计算资源增加所带来的性能增长。在这一区域,性能以越来越慢的趋势持续增长,当片内通信发挥主导作用时,性能达到顶峰。在计算密集型和计算稀疏型模式中,计算资源的充足与否导致没有计算主导或片外主导区域,如图 7(b) 和 7(c) 所示。
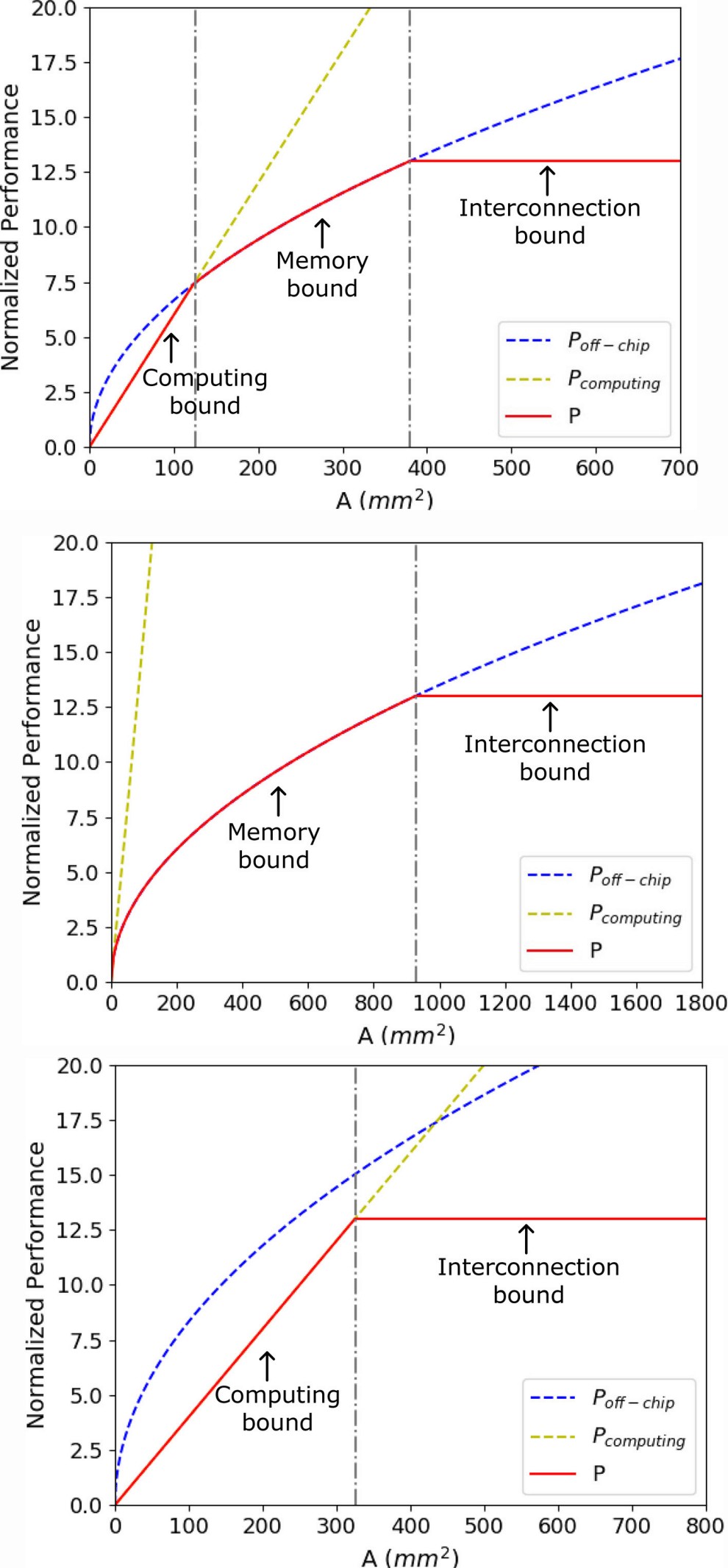
图 7. 性能模型的三种可能趋势。
4.3
与单片多核和多芯片系统的比较
我们将芯粒系统的性能模型与单片多核和多芯粒系统的性能模型进行比较,以证明大芯片系统的性能优势。我们使用的基线设计参数来自AMD的“Zepplin”SoC及其第一代EPYC TM 芯粒处理器[39]。我们假设三个系统的计算能力和片外访问是相同的,那么唯一的区别在于“片内通信”区域。芯粒间和芯片间通信由“Zepplin”SoC 上配备的无限结构 (IF) 和 PCIe 分别提供[39],片外带宽密度通过将其两通道 DDR4 带宽除以SoC 的长边长度。我们设置αoff-chip和αintra-chip分别为 6 和 4。性能曲线如图8所示。
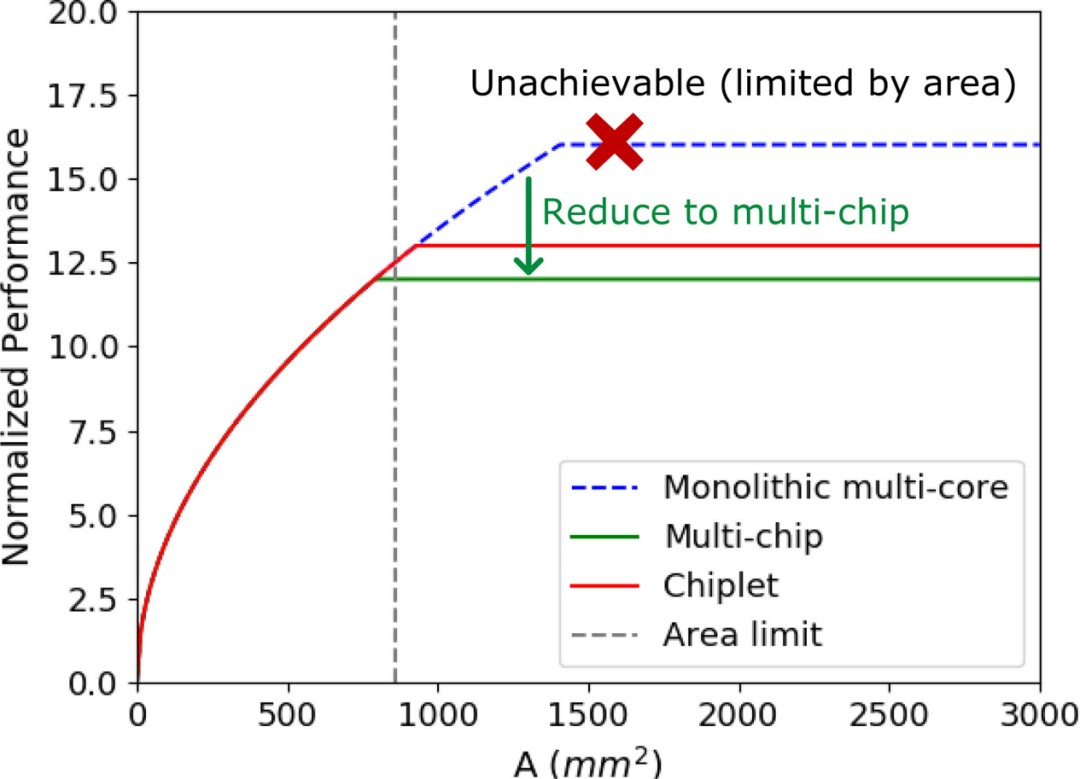
图 8. 芯粒组、单片多核和多芯片系统的性能模型比较。
理想情况下,由于内核间带宽的限制较少,单片芯片比其他两个系统具有更高的峰值性能。然而,单片设计面临着步进式光刻机最大区域尺寸带来的“区域墙”的巨大挑战,这阻碍了性能的增长。为了继续系统扩展,转而采用传统工艺下的多芯片集成技术,在性能曲线上表现为随着面积的增加,渐近线向多芯片设计线发展(图中未标出这一趋势)。由此,我们可以推断出大芯片系统的高性能可扩展性的优势。
4.4
性能优化
性能优化方法通常可分为三个层次:工作负载映射、架构和物理设计。在性能模型中,优化表现为曲线函数或位置的变化。在接下来的章节中,我们将首先以三维堆叠为例,阐明物理设计如何改变性能曲线的形状,然后说明αoff-chip和αintra-chip在我们的模型中扮演的角色及其主导因素。
模型形状的优化。我们采用Tetris 芯粒加速器[40]的2D集成和3D堆叠实现来证实物理设计,特别是集成技术,通过改变性能曲线的形状来从根本上优化芯片性能。
2D 和 3D 实现的主要区别在于片外访问方式。2D Tetris使用 LPDDR3,符合等式 10 中的关系。3D Tetris使用混合存储器立方体(HMC)[41], [42]作为三维存储器基板,与逻辑芯片垂直面对面堆叠,通过高速硅通孔(TSV)通信,那么片外带宽应与面积成正比,如公式 16 所示。
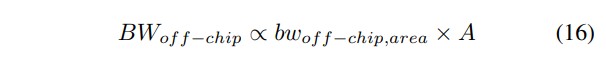
这里,bwoff-chip,area的单位是GBps/mm²
如图 9 所示,我们可以得到两种实现方式的性能模型,其中芯片间带宽来自传统的 HMC 设计。由于采用了高度并行的处理元件,虽然频率不是很高(500MHZ)[40],但计算能力非常强,因此在这两种方案中都不会成为瓶颈。
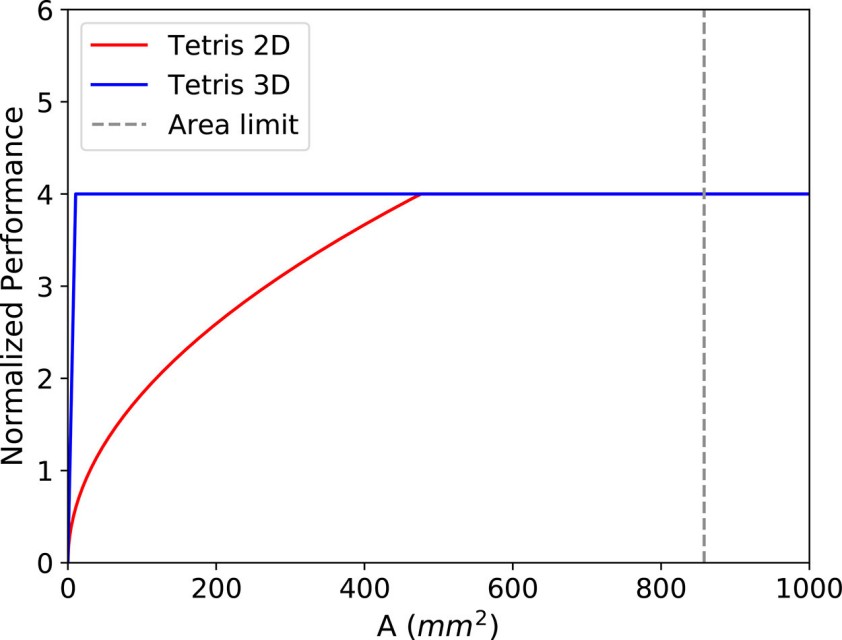
图 9. Tetris二维集成设计和三维堆叠设计的性能模型对比。三维堆叠优化改变了模型曲线的形状。
虽然 3D 实现仍然受到最大硅片面积的限制,但与 2D 设计相比,3D 实现的片外瓶颈区域大大缩小,即使芯片面积较小,也能轻松达到峰值性能,这归功于 3D 存储器堆叠技术提供的丰富布线资源和高速传输。从这个例子中我们可以看出,一项设计工作可能不会对系统的性能做出贡献,但却能在设计者感兴趣的区域带来突出的改进。
αoff-chip和αintra-chip的作用。αoff-chip指芯片与芯片外存储器之间传输的数据量,αintra-chip指通过总线互连的两个芯粒或内核之间传输的最大数据量。虽然它们都是与数据量有关的变量,而且在上文的讨论中假定它们与芯片面积保持不变,但它们会受到芯片内存容量和互连结构等架构设计的影响。
αoff-chip取决于应用,即计算所需的数据量、工作负载映射、调度策略以及架构设计,尤其是芯片内存容量。片外访问的数据量由两部分组成:由工作负载所需的数据量决定的恒定部分,以及由无效的工作负载映射策略或片上内存容量不足造成的冗余部分。随着映射和片上内存比例的改善,数据局部性可以得到优化,αoff-chip也会相应降低,然后在片外区域出现性能曲线,如图 10(a)所示。
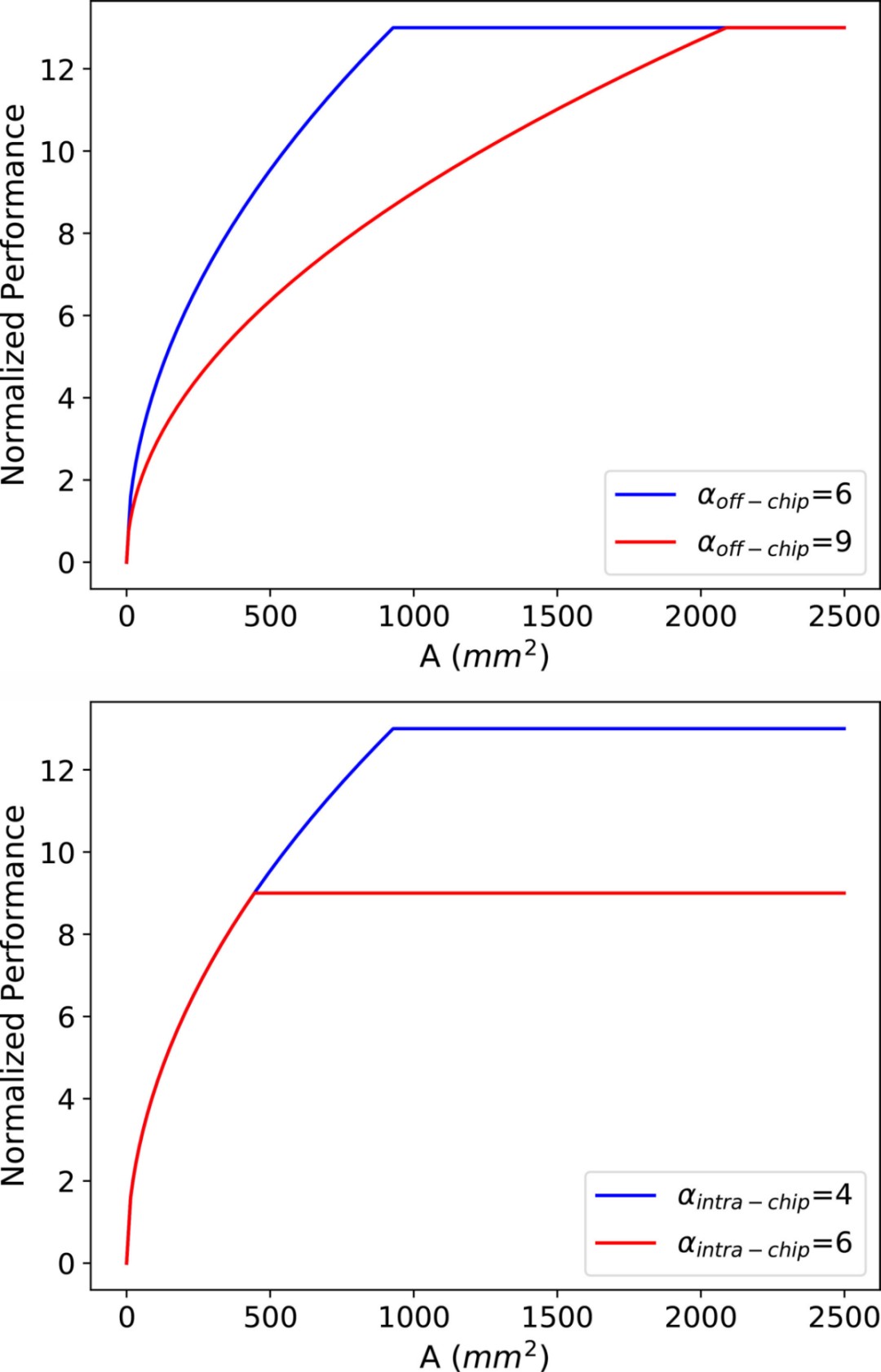
图 10. αoff-chip和αintra-chip的影响。
αintra-chip由应用、芯片内存容量和互连结构决定。应用和片上存储器会影响每个芯片上的数据位置。互联结构的影响可以从更广阔的角度来阐述。考虑到在两个节点之间传输固定数量的数据,它们之间的路由越多,分配到每条路由上的数据就越少,从而导致每条总线传输的数据量减少,最大值也是如此。与网状设计相比,Cmesh 是一种能实现较低αintra-chip值的互连设计。αintra-chip值的降低可提高芯片设计的峰值性能。
5. 架构:构建大芯片
大芯片的架构设计对性能有重大影响,与内存访问模式密切相关。在内存访问模式方面,与传统的多核处理器设计考虑将多核集成在单个裸片上访问内存不同,大芯片设计侧重于多个多核裸片访问内存系统。根据内存访问模式,大芯片可以分为对称芯粒架构、NUMA(非均匀内存访问)芯粒架构、集群芯粒架构和异构芯粒架构。在接下来的章节中,我们将以利用芯粒技术构建大芯片为例,从性能、可扩展性、可靠性、通信等方面讨论这些大芯片架构的特点。
对称芯粒架构。如图 11(a)所示,对称芯粒架构由许多相同的计算芯粒组成,它们通过路由器网络或芯粒间资源(例如中介层)访问共享的统一存储器或IO。芯粒可以设计为具有本地缓存的多核结构,或者具有多个处理元件的NoC结构。统一内存可以被所有芯粒平等地访问,这体现了UMA(统一内存访问)的效果。我们现在讨论对称芯粒架构的三个主要优点。首先,对称芯粒架构允许多个芯粒执行指令以提供高计算能力。工作负载可以分成小块,然后分配给不同的 芯粒,以加快应用程序的执行速度,同时保持不同芯粒之间的工作负载平衡。其次,这种对称的芯粒架构提供了从不同芯粒到内存的统一延迟,无需考虑NUMA等分布式共享内存系统中的远程访问或内存复制,从而节省了由于不必要的数据移动而导致的延迟和能耗。第三,对称芯粒处理器还提供冗余设计,其他芯粒可以接管故障芯粒的工作,从而提高系统可靠性。由于共享内存,对称芯粒处理器可以在不增加额外私有内存的情况下增加芯粒的数量。然而,当对称芯粒架构继续扩大芯粒数量时,互连设计将受到物理布线的严重限制。解决高带宽芯粒间通信和内存请求冲突也具有挑战性。请注意,增加 芯粒 的数量可能会增加不同 芯粒 对存储器的请求冲突,这会损害系统性能。平均而言,内存带宽由芯粒划分。增加芯粒的数量会减少每个芯粒分区内存带宽。工业界和学术界的一些设计采用了对称芯片架构。Apple M1 Ultra 处理器[43]采用了芯粒集成设计,具有两个相同的 M1 Max 芯片,具有统一的内存架构设计。芯片上的核心可以访问高达 128GB 的统一内存。Fotouhi[44]提出了一种基于芯粒集成的统一内存架构,以克服距离相关的功耗和延迟问题。Sharma [45]提出了一种通过板载光学互连共享统一存储器的多芯片系统。
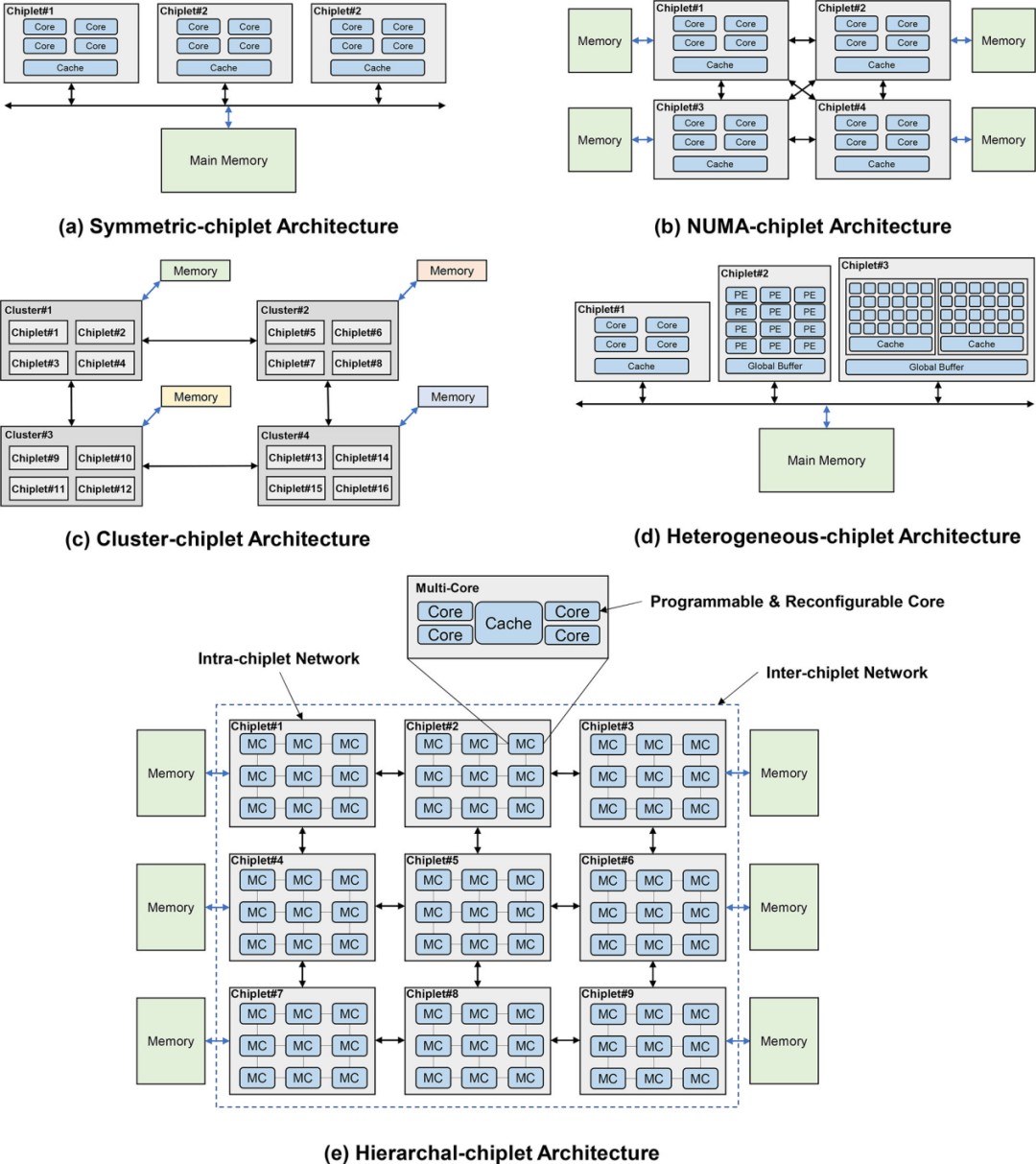
图 11. 大芯片处理器的架构。
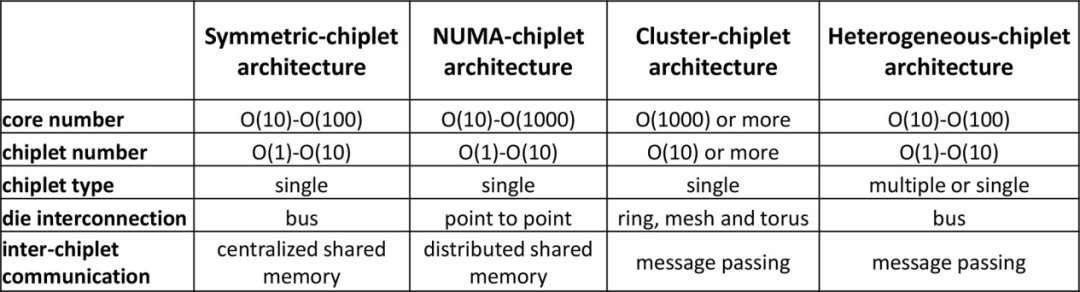
图 12. 大芯片不同架构之间的比较。
NUMA-芯粒架构。NUMA芯粒架构包含通过点对点网络或中央路由器互连的多个芯粒,并且NUMA芯粒架构的存储器系统由所有芯粒共享但分布在架构中,如图11 (b)所示。芯粒可以采用共享缓存的多核设计,或者通过NoC互连的PE的设计。而且,每个芯粒可以占用自己的本地存储器,例如DRAM、HBM等,这是其区别于对称芯粒架构的最明显特征。尽管这些连接到不同芯粒的存储器分布在系统中,但存储器地址空间是全局共享的。共享内存的这种分布式放置会导致 NUMA 效应,即访问远程内存比访问本地内存慢[46]。NUMA-芯粒 架构考虑了一些优点。从单个芯粒的角度来看,每个芯粒都拥有自己的内存,具有相对私有的内存带宽和容量,减少了与其他芯粒的内存请求的冲突。此外,芯片与内存的紧密放置提供了数据移动的低延迟和低功耗。此外,在NUMA-芯粒架构中,通过高带宽点对点网络或路由器互连的多个芯粒可以并行执行任务,从而提高系统性能和兼容性。这种 NUMA 芯粒架构具有很高的可扩展性,因为每个芯粒都有自己的内存。然而,随着 NUMA-芯粒 架构扩展到更多的芯粒,设芯粒到芯粒互连网络变得具有挑战性。此外,随着芯粒数量的增加,编程模型的成本和难度也随之增加。有一些设计采用 NUMA-芯粒 架构。AMD 的第一代 EPYC 处理器将四个相同的芯粒与本地内存连接起来[39]。对内存的本地访问和远程访问之间的延迟差异可达 51ns [46]。在AMD的第二代EPYC处理器中,计算芯粒通过IO芯粒连接到内存,这显示了NUMA-芯粒架构[34]。另一种典型的 NUMA-芯粒 架构设计是 Intel Sapphire Rapids [47]。它由四个芯粒组成,通过 MDFIO(多芯片结构 IO)连接。四个芯粒组织为 2x2 阵列,每个芯片充当 NUMA 节点。Zaruba [48]架构了 4 个基于 RISC-V 处理器的芯粒,每个芯粒都有三个分别与其他三个芯粒的链接,以提供非统一的内存访问。
集群芯粒架构。如图 11(c)所示,集群芯粒架构包含许多芯粒集群,总共有数千个核心。采用环形、网状、一维/二维环面等高速或高吞吐量网络拓扑来连接集群,以满足此类超大规模系统的高带宽和低延迟通信需求。每个集群由许多互连的芯粒和单独的内存组成,并且每个集群都可以运行单独的操作系统。集群可以通过消息传递的方式与其他集群进行通信。通过高性能互连实现强大集群互连的集群-芯粒架构显示出高可扩展性并提供巨大的计算能力。作为一种高度可扩展的架构,集群芯粒架构是许多设计的基础。IntAct [30]集成了 96 个内核,这些内核在有源中介层上分为 6 个芯粒。6 个芯粒通过 NoC 连接。Tesla[49]发布了用于亿级计算的Dojo系统微架构。在 Dojo 中,一个训练图块由 25 个 D1 芯粒组成,这些芯粒排列为 5x5 矩阵样式。通过 2D 网格网络互连的许多训练块可以形成更大的系统。Simba[1]通过 MCM 集成,利用网状互连构建了 6x6 芯粒系统。芯粒 内的 PE 使用 NoC 连接。
异构芯粒架构。异构芯粒架构由不同种类的芯粒组成,如图11(d)所示。同一中介层上的不同种类的芯粒可以与其他种类的芯粒互补,协同执行计算任务。华为鲲鹏920系列SoC[25]是基于计算芯粒、IO 芯粒、AI 芯粒等的异构系统。Intel Lakefield[50]提出了将计算芯粒堆叠在基础芯粒上的设计。计算芯粒集成了许多处理核心,包括CPU、GPU、IPU(基础设施处理单元)等,基础芯粒包含丰富的IO接口,包括PCIe Gen3、USB type-C等。在Ponte Vecchio[51]中,有两个基础tile使用EMIB(嵌入式多芯片互连桥)互连。计算tile和 RAMBO tile堆叠在每个基础tile上。Intel Meteor Lake处理器[52]集成了GPU tile、CPU tile、IO tile和SoC tile。
对于当前和未来的亿亿级计算,我们预测分层芯粒架构将是一种强大而灵活的解决方案。如图11 (e)所示,分层芯粒架构被设计为具有分层互连的多个内核和多个芯粒。在芯粒内部,内核使用超低延迟互连进行通信,而芯粒之间则以得益于先进封装技术的低延迟互连,从而在这种高可扩展性系统中实现片上延迟和NUMA效应可以最小化。存储器层次结构包含核心存储器、片内存储器和片外存储器。这三个级别的内存在内存带宽、延迟、功耗和成本方面有所不同。在分层芯粒架构的概述中,多个核心通过交叉交换机连接并共享缓存。这就形成了一个pod结构,并且pod通过芯粒内网络互连。多个pod形成一个芯粒,芯粒通过芯粒间网络互连,然后连接到片外存储器。需要仔细设计才能充分利用这种层次结构。合理利用内存带宽来平衡不同计算层次的工作负载可以显着提高芯粒系统效率。正确设计通信网络资源可以确保芯粒协同执行共享内存任务。
6. 构建大芯片:我们的实现
为了探索大芯片的设计和实现技术,我们架构和设计了一个基于 16 芯粒的 256 核处理器系统,命名为浙江大芯片。在此,我们将介绍所提出的大芯片处理器。
浙江大芯片采用可扩展的基于瓦片的架构,如图13所示。该处理器由 16 个小芯粒组成,并且有可能扩展到 100 个小芯粒。每个芯粒中都有16个CPU 处理器,通过片上网络(NOC) 连接,每个tile 完全对称互连,以实现多个芯粒之间的通信。CPU处理器是基于RISC-V指令集设计的。此外,该处理器采用统一内存系统,这意味着任何tile上的任何核心都可以直接访问整个处理器的内存。
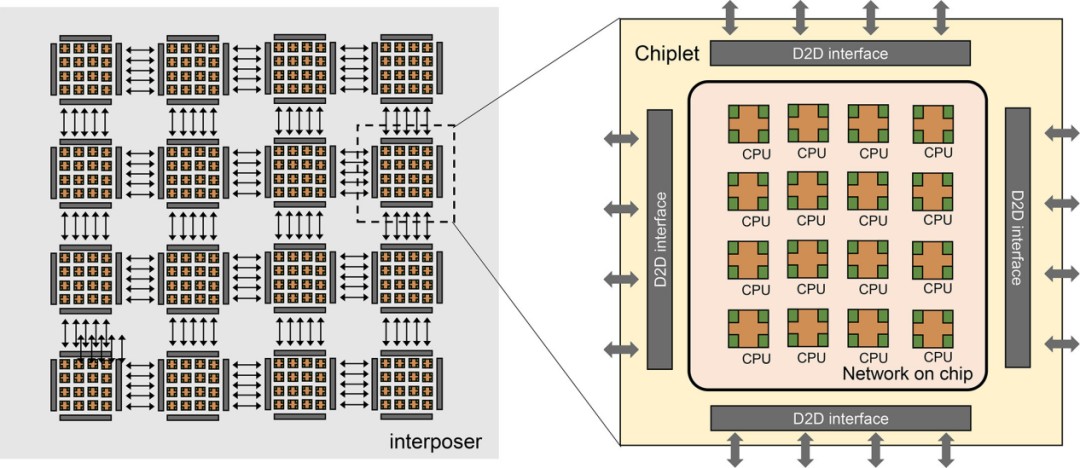
图 13. 浙江大芯片概况
为了连接多个小芯粒,采用了芯片间 (D2D) 接口。该接口采用基于时分复用机制的通道共享技术进行设计。这种方法减少了芯片间信号的数量,从而最大限度地减少了 I/O 凸块和内插器布线资源的面积开销,从而可以显着降低基板设计的复杂性。小芯粒终止于构建微型 I/O 焊盘的顶部金属层。浙江大芯处理器采用22 nm CMOS工艺设计和制造。
7. 前景与挑战
除了提高计算能力,大芯片还将促进新型设计方法的发展。我们预测,近存计算和光电计算将是重要的研究方向。
7.1
近存计算
由于计算工作量大量集中在芯粒中,片外存储系统通常具有简单的存储数据和IO的功能。对于数据局部性较差的应用,频繁发生片内缓存未命中,导致需要从片外存储器重新加载数据。大量芯粒和内存之间频繁的数据移动可能会导致额外的延迟和高能耗。在对称芯粒架构中,总线拥塞会使这种情况恶化,从而降低系统性能。为了解决这些问题,可以使用近数据处理来引入近存计算,将处理和内存单元与高带宽互连紧密放置,以最大限度地提高系统性能。近存计算打破了传统内存层次结构的性能限制。3D 堆栈内存是近存计算的一个很好的例子,其作为容量、带宽和性能限制的解决方案而受到越来越多的关注。在3D堆叠存储器中,多个DRAM芯粒垂直堆叠在底部逻辑芯粒上,TSV实现芯粒之间的电气连接,表现出芯粒间数据传输的高带宽。位于堆叠存储器底部的逻辑芯粒可以进行相对简单的数据处理,承担部分计算工作量。近存计算的另一种方法是增加片内缓存的容量,以在片上保留更多数据,而不是频繁调度片内和片外数据。AMD提出了3D V-cache技术,在Zen3共享的32MB L3缓存上堆叠64MB缓存,总共实现96MB L3缓存。Cerebras WSE 甚至实现了 18GB 片上内存。
7.2
光电子计算
光电子计算已成为解决电气设计瓶颈的潜在方案,尤其是用于芯片间通信的电气 IO,随着高带宽需求的增加,这一瓶颈变得更加突出 [53]、[54]、[55]。目前,电气互连的数据速率、引脚数和引脚间距都受到串扰等信号完整性问题的限制。此外,一些引脚被保留用于电源/接地引脚等非通信目的,进一步降低了引脚利用率,加剧了阻碍芯片间高带宽通信的互连物理限制。然而,限制芯粒之间的距离可能会导致与远程芯粒通信的多跳,这进一步影响系统性能。
本文定义的光 IO 处理器是未来的一项重要技术,它利用 IO 芯片和光学设备促进高带宽通信。光 IO 处理器能克服传统电气互连的信号完整性限制,使其成为解决上述电气设计问题的有吸引力的解决方案。研究[53]、[54]、[55]、[56]、[57]说明了高性能、低能耗光 IO 实现和封装的可行性。
7.3
挑战
大芯片虽然可以实现强大的计算能力,但仍面临良率、散热和性能等主要挑战。首先,大芯片的集成步骤较多,受器件、技术、环境等因素影响,难以保证高良率。虽然 KGD 等方法可以提高良率,但也必须考虑缺陷芯片的设计成本。其次,散热是大芯片设计中的一个重要问题,大量芯片会产生大量热量。因此,散热系统和低功耗设计至关重要。最后,大芯片设计中的任务映射和设计空间探索实施起来具有挑战性。此外,在芯粒集成中,必须考虑不均匀带宽效应。
参考文献:
[1] Yakun Sophia Shao, Jason Clemons, Rangharajan Venkatesan, Brian Zimmer, Matthew Fojtik, Nan Jiang, Ben Keller, Alicia Klinefelter, Nathaniel Pinckney, Priyanka Raina, et al. Simba: Scaling deep-learning inference with multi-chip-module-based architecture. In Proceedings of the 52nd Annual IEEE/ACM International Symposium on Microarchi tecture, pages 14–27, 2019.
[2] Gordon E Moore. Cramming more components onto integrated circuits, reprinted from electronics, volume 38, number 8, april 19, 1965, pp. 114 ff. IEEE solid-state circuits society newsletter, 11(3):33–35, 2006.
[3] Robert H Dennard, Fritz H Gaensslen, Hwa-Nien Yu, V Leo Rideout, Ernest Bassous, and Andre R LeBlanc. Design of ion-implanted mosfet’s with very small physical dimensions. IEEE Journal of solid-state circuits, 9(5):256–268, 1974.
[4] John H Lau. Semiconductor advanced packaging. Springer Nature, 2021.
[5] Jens Timo Neumann, Paul Graupner, Winfried Kaiser, Reiner Garreis, ¨ and Bernd Geh. Interactions of 3d mask effects and na in euv lithography. In Photomask Technology 2012, volume 8522, pages 322– 333. SPIE, 2012.
[6] Yinxiao Feng and Kaisheng Ma. Chiplet actuary: A quantitative cost model and multi-chiplet architecture exploration. In Proceedings of the 59th ACM/IEEE Design Automation Conference, pages 121–126, 2022.
[7] Dylan Stow, Itir Akgun, and Yuan Xie. Investigation of cost-optimal network-on-chip for passive and active interposer systems. In 2019 ACM/IEEE International Workshop on System Level Interconnect Pre diction (SLIP), pages 1–8. IEEE, 2019.
[8] Fuping Li, Ying Wang, Yuanqing Cheng, Yujie Wang, Yinhe Han, Huawei Li, and Xiaowei Li. Gia: A reusable general interposer architecture for agile chiplet integration. In Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design, pages 1–9, 2022.
[9] Hao Zheng, Ke Wang, and Ahmed Louri. A versatile and flexible chiplet-based system design for heterogeneous manycore architectures. In 2020 57th ACM/IEEE Design Automation Conference (DAC), pages 1–6. IEEE, 2020.
[10] Florian Zaruba, Fabian Schuiki, and Luca Benini. Manticore: A 4096- core risc-v chiplet architecture for ultraefficient floating-point comput ing. IEEE Micro, 41(2):36–42, 2020.
[11] Zhanhong Tan, Hongyu Cai, Runpei Dong, and Kaisheng Ma. Nn baton: Dnn workload orchestration and chiplet granularity exploration for multichip accelerators. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pages 1013–1026. IEEE, 2021.
[12] Samuel Naffziger, Kevin Lepak, Milam Paraschou, and Mahesh Subra mony. 2.2 amd chiplet architecture for high-performance server and desktop products. In 2020 IEEE International Solid-State Circuits Conference-(ISSCC), pages 44–45. IEEE, 2020.
[13] Mu-Shan Lin, Tze-Chiang Huang, Chien-Chun Tsai, King-Ho Tam, Kenny Cheng-Hsiang Hsieh, Ching-Fang Chen, Wen-Hung Huang, Chi Wei Hu, Yu-Chi Chen, Sandeep Kumar Goel, et al. A 7-nm 4-ghz arm1- core-based cowos1chiplet design for high-performance computing. IEEE Journal of Solid-State Circuits, 55(4):956–966, 2020.
[14] Jinwoo Kim, Gauthaman Murali, Heechun Park, Eric Qin, Hyoukjun Kwon, Venkata Chaitanya Krishna Chekuri, Nael Mizanur Rahman, Nihar Dasari, Arvind Singh, Minah Lee, et al. Architecture, chip, and package codesign flow for interposer-based 2.5-d chiplet integration enabling heterogeneous ip reuse. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 28(11):2424–2437, 2020.
[15] MD Arafat Kabir and Yarui Peng. Chiplet-package co-design for 2.5 d systems using standard asic cad tools. In 2020 25th Asia and South Pacific Design Automation Conference (ASP-DAC), pages 351– 356. IEEE, 2020.
[16] Ranggi Hwang, Taehun Kim, Youngeun Kwon, and Minsoo Rhu. Cen taur: A chiplet-based, hybrid sparse-dense accelerator for personalized recommendations. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), pages 968–981. IEEE, 2020.
[17] Brian Zimmer, Rangharajan Venkatesan, Yakun Sophia Shao, Jason Clemons, Matthew Fojtik, Nan Jiang, Ben Keller, Alicia Klinefelter, Nathaniel Pinckney, Priyanka Raina, et al. A 0.32–128 tops, scalable multi-chip-module-based deep neural network inference accelerator with ground-referenced signaling in 16 nm. IEEE Journal of Solid-State Circuits, 55(4):920–932, 2020.
[18] Akiyoshi Suzuki. Advances in optics and exposure devices employed in excimer laser/euv lithography. Handbook of Laser Micro-and Nano Engineering, pages 1–42, 2020.
[19] Bernhard Kneer, Sascha Migura, Winfried Kaiser, Jens Neumann, and Jan Schoot. Euv lithography optics for sub 9 nm resolution. Proc. SPIE, 9422, 03 2015.
[20] Burn J Lin. Where is the lost resolution? In Optical Microlithography V, volume 633, pages 44–50. SPIE, 1986.
[21] James A Cunningham. The use and evaluation of yield models in integrated circuit manufacturing. IEEE Transactions on Semiconductor Manufacturing, 3(2):60–71, 1990.
[22] Dylan Stow, Yuan Xie, Taniya Siddiqua, and Gabriel H Loh. Cost effective design of scalable high-performance systems using active and passive interposers. In 2017 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pages 728–735. IEEE, 2017.
[23] Tianqi Tang and Yuan Xie. Cost-aware exploration for chiplet-based architecture with advanced packaging technologies. arXiv preprint arXiv:2206.07308, 2022.
[24] Noah Beck, Sean White, Milam Paraschou, and Samuel Naffziger. zeppelin: An soc for multichip architectures. In 2018 IEEE International Solid - State Circuits Conference - (ISSCC), pages 40–42, 2018.
[25] Jing Xia, Chuanning Cheng, Xiping Zhou, Yuxing Hu, and Peter Chun. Kunpeng 920: The first 7-nm chiplet-based 64-core arm soc for cloud services. IEEE Micro, 41(5):67–75, 2021.
[26] Gary Lauterbach. The path to successful wafer-scale integration: The cerebras story. IEEE Micro, 41(6):52–57, 2021.
[27] Wafer-scale deep learning. In 2019 IEEE Hot Chips 31 Symposium (HCS), pages 1–31, 2019.
[28] Sean Lie. Cerebras architecture deep dive: First look inside the hw/sw co-design for deep learning : Cerebras systems. In 2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–34, 2022.
[29] Shu-Rong Chun, Tin-Hao Kuo, Hao-Yi Tsai, Chung-Shi Liu, Chuei-Tang Wang, Jeng-Shien Hsieh, Tsung-Shu Lin, Terry Ku, and Douglas Yu. Info sow (system-on-wafer) for high performance computing. In 2020 IEEE 70th Electronic Components and Technology Conference (ECTC), pages 1–6. IEEE, 2020.
[30] Pascal Vivet, Eric Guthmuller, Yvain Thonnart, Gael Pillonnet, Csar Fuguet, Ivan Miro-Panades, Guillaume Moritz, Jean Durupt, Christian Bernard, Didier Varreau, Julian Pontes, Sbastien Thuries, David Coriat, Michel Harrand, Denis Dutoit, Didier Lattard, Lucile Arnaud, Jean Charbonnier, Perceval Coudrain, Arnaud Garnier, Frdric Berger, Alain Gueugnot, Alain Greiner, Quentin L. Meunier, Alexis Farcy, Alexandre Arriordaz, Sverine Chramy, and Fabien Clermidy. Intact: A 96-core processor with six chiplets 3d-stacked on an active interposer with distributed interconnects and integrated power management. IEEE Journal of Solid-State Circuits, 56(1):79–97, 2021.
[31] Po-Yao Lin, M. C. Yew, S. S. Yeh, S. M. Chen, C. H. Lin, C. S. Chen, C. C. Hsieh, Y. J. Lu, P. Y. Chuang, H. K. Cheng, and Shin-Puu Jeng. Reliability performance of advanced organic interposer (cowos-r) packages. In 2021 IEEE 71st Electronic Components and Technology Conference (ECTC), pages 723–728, 2021.
[32] M.L. Lin, M.S. Liu, H.W. Chen, S.M. Chen, M.C. Yew, C.S. Chen, and Shin-Puu Jeng. Organic interposer cowos-r+ (plus) technology. In 2022 IEEE 72nd Electronic Components and Technology Conference (ECTC), pages 1–6, 2022.
[33] Jinwoo Kim, Gauthaman Murali, Heechun Park, Eric Qin, Hyoukjun Kwon, Venkata Chaitanya Krishna Chekuri, Nael Mizanur Rahman, Nihar Dasari, Arvind Singh, Minah Lee, Hakki Mert Torun, Kallol Roy, Madhavan Swaminathan, Saibal Mukhopadhyay, Tushar Krishna, and Sung Kyu Lim. Architecture, chip, and package codesign flow for interposer-based 2.5-d chiplet integration enabling heterogeneous ip reuse. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 28(11):2424–2437, 2020.
[34] Samuel Naffziger, Kevin Lepak, Milam Paraschou, and Mahesh Subra mony. 2.2 amd chiplet architecture for high-performance server and desktop products. In 2020 IEEE International Solid- State Circuits Conference - (ISSCC), pages 44–45, 2020.
[35] Mengdi Wang, Ying Wang, Cheng Liu, and Lei Zhang. Network-on interposer design for agile neural-network processor chip customization. In 2021 58th ACM/IEEE Design Automation Conference (DAC), pages 49–54. IEEE, 2021.
[36] Larry Gilg and Y Zorian. Known good die. Multi-Chip Module Test Strategies, pages 15–25, 1997.
[37] Xiaohan Ma, Ying Wang, Yujie Wang, Xuyi Cai, and Yinhe Han. Survey on chiplets: interface, interconnect and integration methodology. CCF Transactions on High Performance Computing, pages 1–10, 2022.
[38] Subramanian S Iyer. Heterogeneous integration for performance and scaling. IEEE Transactions on Components, Packaging and Manufac turing Technology, 6(7):973–982, 2016.
[39] Noah Beck, Sean White, Milam Paraschou, and Samuel Naffziger. zeppelin: An soc for multichip architectures. In 2018 IEEE International Solid-State Circuits Conference-(ISSCC), pages 40–42. IEEE, 2018.
[40] Mingyu Gao, Jing Pu, Xuan Yang, Mark Horowitz, and Christos Kozyrakis. Tetris: Scalable and efficient neural network acceleration with 3d memory. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, pages 751–764, 2017.
[41] Hybrid memory cube Consortium. Hybrid memory cube specification 2.1. Last Revision, 2013.
[42] Joe Jeddeloh and Brent Keeth. Hybrid memory cube new dram architecture increases density and performance. In 2012 symposium on VLSI technology (VLSIT), pages 87–88. IEEE, 2012.
[43] Apple Newsroom. Apple unveils m1 ultra, the worlds most powerful chip for a personal computer, 2022. https: //www.apple.com/hk/en/newsroom/2022/03/apple-unveils-m1-ultra-the worlds-most-powerful-chip-for-a-personal-computer/, Last accessed on 2022-11-18.
[44] Pouya Fotouhi, Sebastian Werner, Jason Lowe-Power, and SJ Ben Yoo. Enabling scalable chiplet-based uniform memory architectures with silicon photonics. In Proceedings of the International Symposium on Memory Systems, pages 222–334, 2019.
[45] Arastu Sharma, Nikolaos Bamiedakis, Fotini Karinou, and Richard Penty. Multi-chiplet system architecture with shared uniform access memory based on board-level optical interconnects. In 2021 Optical Fiber Communications Conference and Exhibition (OFC), pages 1–3. IEEE, 2021.
[46] Samuel Naffziger, Noah Beck, Thomas Burd, Kevin Lepak, Gabriel H Loh, Mahesh Subramony, and Sean White. Pioneering chiplet technol ogy and design for the amd epyc and ryzen processor families: Industrial product. In 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), pages 57–70. IEEE, 2021.
[47] Nevine Nassif, Ashley O. Munch, Carleton L. Molnar, Gerald Pasdast, Sitaraman V. Lyer, Zibing Yang, Oscar Mendoza, Mark Huddart, Srikr ishnan Venkataraman, Sireesha Kandula, Rafi Marom, Alexandra M. Kern, Bill Bowhill, David R. Mulvihill, Srikanth Nimmagadda, Varma Kalidindi, Jonathan Krause, Mohammad M. Haq, Roopali Sharma, and Kevin Duda. Sapphire rapids: The next-generation intel xeon scalable processor. In 2022 IEEE International Solid- State Circuits Conference (ISSCC), volume 65, pages 44–46, 2022.
[48] Florian Zaruba, Fabian Schuiki, and Luca Benini. Manticore: A 4096- core risc-v chiplet architecture for ultraefficient floating-point comput ing. IEEE Micro, 41(2):36–42, 2021.
[49] Emil Talpes, Douglas Williams, and Debjit Das Sarma. Dojo: The microarchitecture of teslas exa-scale computer. In 2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–28, 2022.
[50] Wilfred Gomes, Sanjeev Khushu, Doug B. Ingerly, Patrick N. Stover, Nasirul I. Chowdhury, Frank O’Mahony, Ajay Balankutty, Noam Dolev, Martin G. Dixon, Lei Jiang, Surya Prekke, Biswajit Patra, Pavel V. Rott, and Rajesh Kumar. 8.1 lakefield and mobility compute: A 3d stacked 10nm and 22ffl hybrid processor system in 1212mm2, 1mm package-on package. In 2020 IEEE International Solid- State Circuits Conference - (ISSCC), pages 144–146, 2020.
[51] Wilfred Gomes, Altug Koker, Pat Stover, Doug Ingerly, Scott Siers, Srikrishnan Venkataraman, Chris Pelto, Tejas Shah, Amreesh Rao, Frank O’Mahony, Eric Karl, Lance Cheney, Iqbal Rajwani, Hemant Jain, Ryan Cortez, Arun Chandrasekhar, Basavaraj Kanthi, and Raja Koduri. Ponte vecchio: A multi-tile 3d stacked processor for exascale computing. In 2022 IEEE International Solid- State Circuits Conference (ISSCC), volume 65, pages 42–44, 2022.
[52] Wilfred Gomes, Slade Morgan, Boyd Phelps, Tim Wilson, and Erik Hallnor. Meteor lake and arrow lake intel next-gen 3d client architecture platform with foveros. In 2022 IEEE Hot Chips 34 Symposium (HCS), pages 1–40, 2022.
[53] Kaveh Hosseini, Edwin Kok, Sergey Y Shumarayev, Chia-Pin Chiu, Arnab Sarkar, Asako Toda, Yanjing Ke, Allen Chan, Daniel Jeong, Mason Zhang, et al. 8 tbps co-packaged fpga and silicon photonics optical io. In 2021 Optical Fiber Communications Conference and Exhibition (OFC), pages 1–3. IEEE, 2021.
[54] Mark Wade, Michael Davenport, Marc De Cea Falco, Pavan Bhargava, John Fini, Derek Van Orden, Roy Meade, Evelina Yeung, Rajeev Ram, Milos Popovi ˇ c, et al. A bandwidth-dense, low power electronic-photonic ´ platform and architecture for multi-tbps optical i/o. In 2018 European Conference on Optical Communication (ECOC), pages 1–3. IEEE, 2018.
[55] Mark Wade, Erik Anderson, Shahab Ardalan, Pavan Bhargava, Sidney Buchbinder, Michael L Davenport, John Fini, Haiwei Lu, Chen Li, Roy Meade, et al. Teraphy: a chiplet technology for low-power, high bandwidth in-package optical i/o. IEEE Micro, 40(2):63–71, 2020.
[56] Roy Meade, Shahab Ardalan, Michael Davenport, John Fini, Chen Sun, Mark Wade, Alexandra Wright-Gladstein, and Chong Zhang. Teraphy: a high-density electronic-photonic chiplet for optical i/o from a multi chip module. In 2019 Optical Fiber Communications Conference and Exhibition (OFC), pages 1–3. IEEE, 2019.
[57] Chen Sun, Daniel Jeong, Mason Zhang, Woorham Bae, Chong Zhang, Pavan Bhargava, Derek Van Orden, Shahab Ardalan, Chandarasekaran Ramamurthy, Erik Anderson, et al. Teraphy: An o-band wdm electro optic platform for low power, terabit/s optical i/o. In 2020 IEEE Symposium on VLSI Technology, pages 1–2. IEEE, 2020.
本文为专栏作者授权创业邦发表,版权归原作者所有。文章系作者个人观点,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







