
编者按:本文来自微信公众号刘言飞语(ID: liufeinotes),创业邦经授权转载。
今天想聊聊关于音乐产品的一些观察和思考。
许多人会说,音乐产品的战争就是版权战争,版权买差不多了,音乐产品也就分出胜负了。实则不然。在腾讯系(QQ音乐、酷狗、酷我)早年间在华语流行领域建立版权优势前提下,网易云音乐还是坚守住了阵地,有了黏性的用户,形成今日的两强格局。
背后的原理是什么呢?我们可以展开说下,用户有关听音乐的需求阶段。
在决策层,要有发现音乐的途径。这种途径,一方面是站外通过热门的综艺、影视剧、公域(微博)或私域(朋友圈)的推荐,另一方面,是产品内通过歌单、推荐等功能实现。
在消费层,当然最重要的就是先要可以听(有版权的曲库),播放的体验(播放器)。除了单纯的听歌消费,围绕着社区互动而展开的 UGC 歌单、歌曲评论、动态分享等,也会变成音乐体验的重要一环。
整体的价值逻辑是这样的:
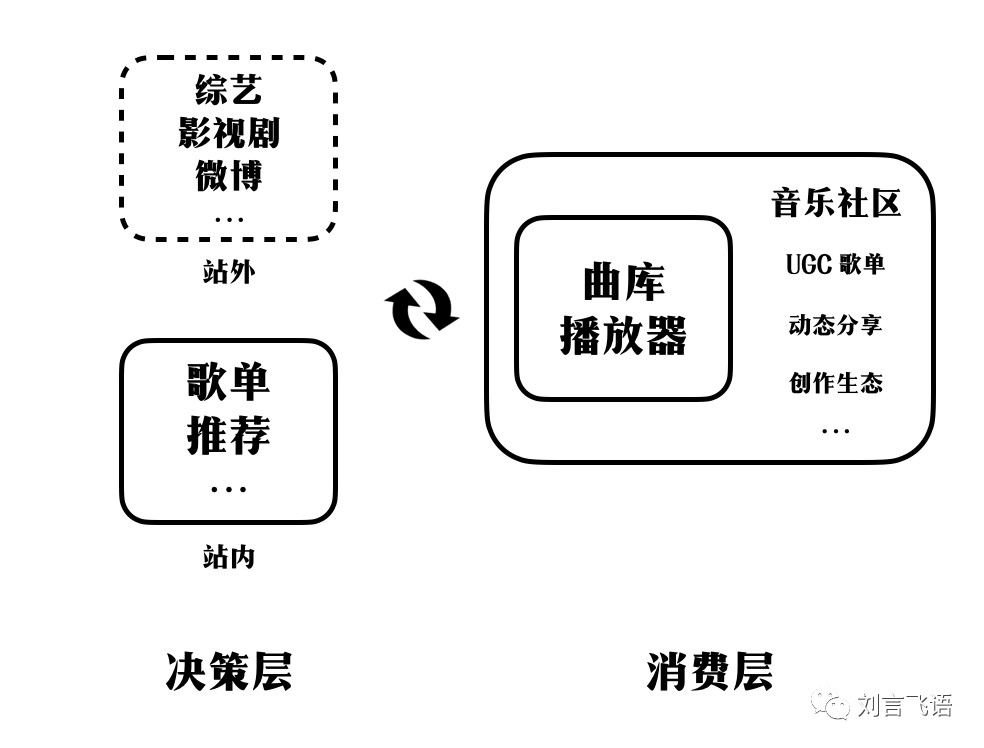
逐个来说。
1.足够大的曲库
关于版权的争夺由来已久。早在 2015 年(听起来都那么远古了),阿里就跟腾讯争抢过不少独家版权。那个年代阿里一度有超过 60% 的中文歌曲独家版权。但虾米和天天动听的发展却还是让人觉得可惜。
网易云音乐也是在那几年突然崛起的,在华语流行版权并不占优势的情况下,甩开了其他对手。
看历史发展也能得出结论:没有版权是万万不行的,但只有版权也是万万不可的。
2.决策场景和消费场景
播放器方面,体验很难能拉开大的差异,无非是封面图的展示方式、歌词的展示和定位、播放的设置等等。并不是说创新难,而是创新的任何功能,对手都能轻松抄去。
在消费场景上可突破的,显然不如在决策场景上可突破的。
决策场景要解决的是:用户想听歌的时候,去哪里找歌。
站外的决策难以影响,在产品内就是兵家必争之地。网易云音乐的“发现”标签页,和 QQ 音乐的“推荐”标签页,是最核心的页面。

他们起到的核心作用就是推荐。
可以联想到淘宝为什么对微信和拼多多非常忌惮:假如用户的决策过程都在微信里完成了,那是多么可怕的事情。而庞大完整的熟人关系链、朋友圈和公众号公私全包的内容平台,简直是消费决策的温床。
还可以类比高德对滴滴的威胁:一旦高德的打车心智在用户心里建立稳固了,滴滴会沦为运力供应公司(大型出租车公司)。
所以反过来看就知道做推荐的价值多大了。把握了决策环节,至少会有这些衍生价值:
通过更佳的使用体验增加用户留存
通过更多使用场景增加用户活跃
B端的广告价值(品牌效果均可)
推荐是重中之重,做的方式有两种:UGC 和系统推荐。
这两种方式都可以“发现内容”,在不同内容载体上出现了明确的产品形态区分。比如电商里,淘宝的“有好货”就是系统推荐,直播带货就是 UGC。知乎里,推荐页面是系统推荐,收藏夹就是 UGC。
下面着重说下个性化推荐。有机会再聊 UGC。
3.个性化推荐方法
发现/推荐音乐的方式有很多,有多个维度可以拆解。
第一个维度,是基于什么推荐。
推荐系统是个庞大的复杂问题,在文内不宜展开讲。底层逻辑则可以用两种常见的协同过滤(Collaborative Filtering)算法举例。
基于用户的协同过滤(UserCF),指的是给用户A的推荐,参考爱好跟A相似的用户B的情况。这种方法在亚马逊发扬光大,国内的豆瓣早期是代表。如今电商平台、内容平台也都普遍使用。
基于内容的协同过滤(ItemCF),指的是用户A的推荐,参考A之前喜欢的内容。同样也是常见算法,适用于已经有足够的用户内容喜好数据的场景。
很显然的,ItemCF 只能源源不断给用户推荐已经喜欢听的音乐,不能让用户发现新的音乐类型。一直听摇滚的,就永远是摇滚;一直听流行的,也不会发现摇滚。UserCF 能相对好一些,虽然一直听摇滚,但有相似的用户开始喜欢上流行摇滚了,那也会被推荐流行摇滚。
第二个维度,是采用哪些数据。
如何量化“喜欢”,通常是通过用户行为,计算一个合理的模型来做量化。公开信息里没有找到详细的描述,但可以间接判断出,音乐产品通常是会采用这些数据的:
播放(及完播情况)
下载
收藏
搜索
评论
分享
主动选择不喜欢
得到喜欢的量化情况,在使用协同过滤时,还要量化“相似”。常见的有余弦相似度,计算空间向量夹角余弦。这个不展开说了,但很有趣,对算法逻辑感兴趣的可以搜下。
第三个维度,是达到怎样的目的。
从终极目的看,当然是用户的活跃和留存。不过中间的二级指标,才是模型可控的,比如推荐转化率(接受程度)、完播情况等等。
但这两个指标主要还是考虑准确率。还有像刚刚提到的:我虽然平时经常听A风格,但也需要听B风格的歌。毕竟喜欢某个歌手,反复狂推他的歌肯定没错,但容易让用户觉得,推荐不到新的内容。
这就要考虑召回率。这背后是多样性和新颖性,也可以用指标来体现,比如歌曲相似情况的方差、每轮推荐里是否有方差较大的歌,等等。
比如我最近听中文流行和民谣比较多,但歌单里还是出现了一首英文歌和一首韩文歌。

另外,真实情况下,还要考虑各种特殊的场景。网易云音乐官方就做了这样一个说明:
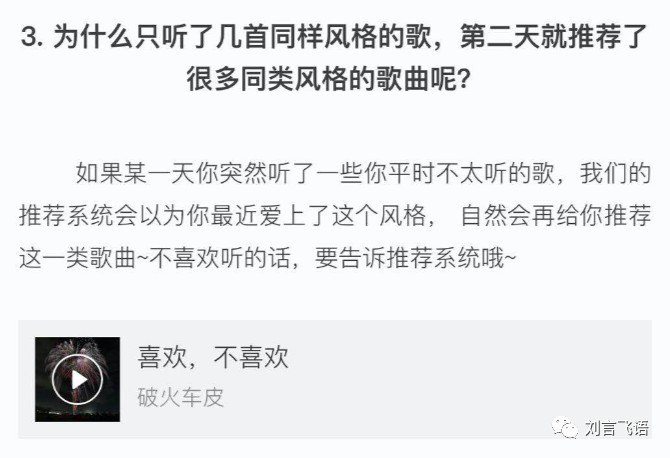
第四个维度,是推荐的对象。
歌曲是一个颗粒度,歌单则是另外一个重要的颗粒度。歌单比起歌曲来有这样的好处:
其一,对用户的容错率高。歌单的 30 首歌里有 20 首满意也可以接受。但歌曲推荐不成功,用户就对功能失望。电台处于二者之间,用户对无预期的播放列表,容错率也不是很高。
其二,以歌单为维度设计模型更容易实现多样化目标。比如刚刚提到的新颖程度,歌单容易实现。而单首歌曲的推荐就不太容易实现。
所以我们看到,QQ 音乐和网易云音乐几乎都是歌单推荐为主。
4.说说体验
网易云音乐和 QQ 音乐的每日推荐都在各自推荐/发现页很显著的位置。
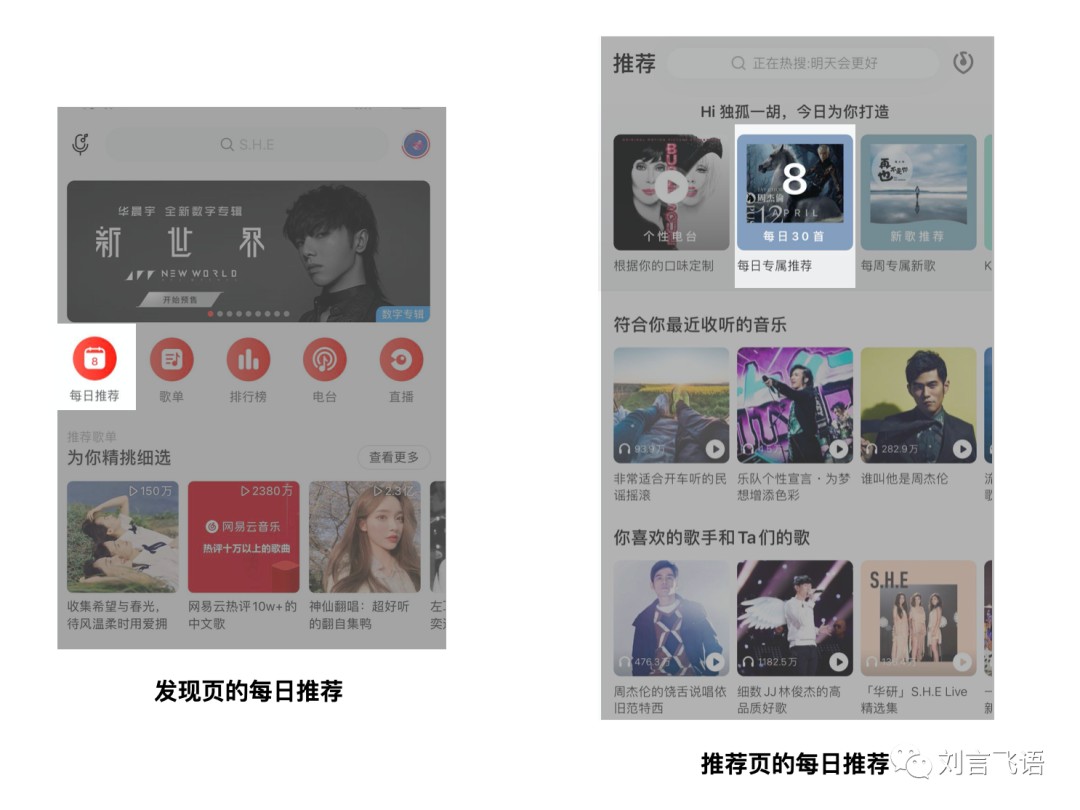
推荐的歌曲都是 30+首。维度也相似,大多是常听的风格,少数是有些陌生的风格。
从个人体验上而言,我几乎只用网易云音乐,当然并非只因为推荐做得好,更多是我平时听歌在网易云音乐比较多,QQ 音乐想推荐好力不能及。
看公众评价的话,网易云音乐起步更早,目前的好评也更多。
另外,《界面》在 2017 年就提到,网易云音乐的曲库使用率高达 80%。这很大程度上是个性化推荐的功劳。说明在个性化推荐的多样化和新颖性上做得出色。
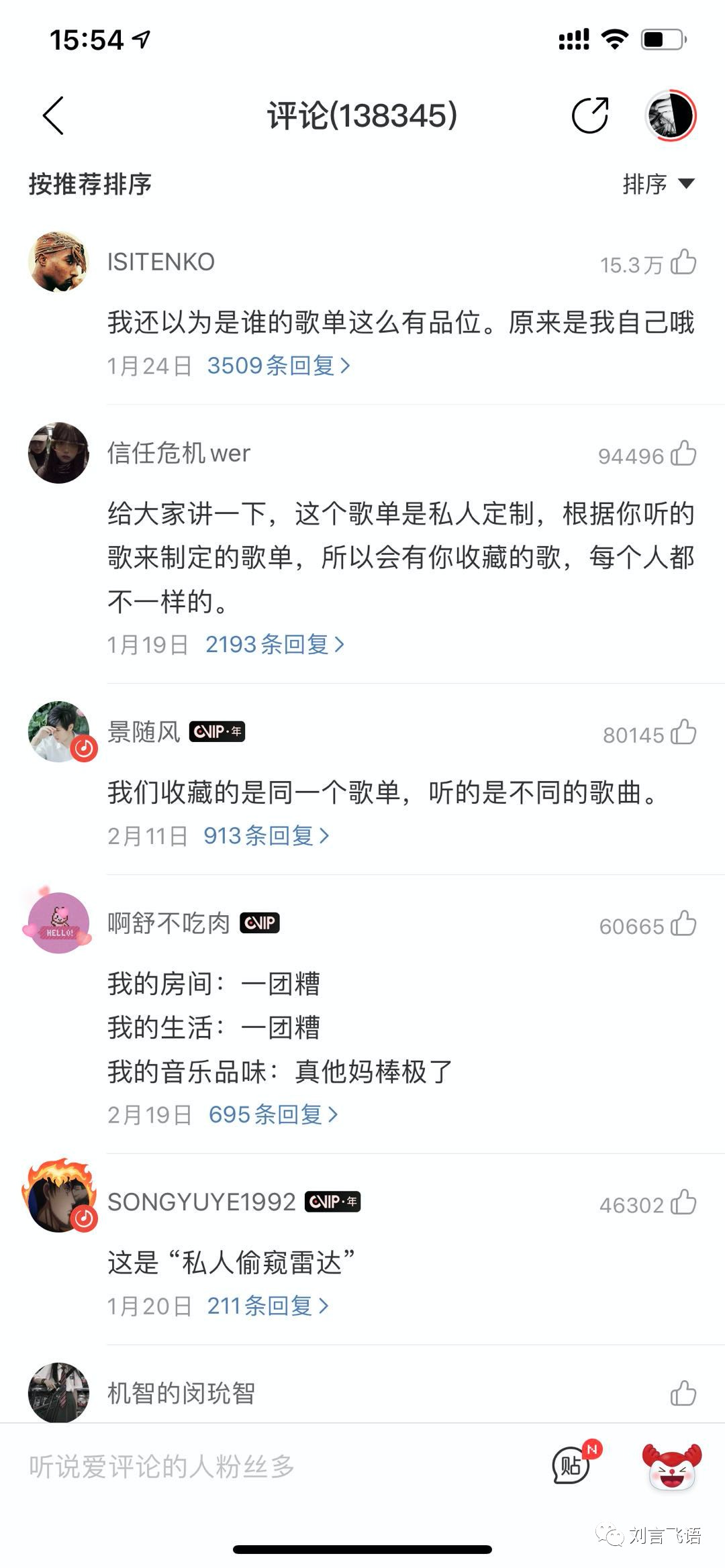
有意思的是,网易云音乐最近上线了一个叫“私人雷达”的功能,呈现为歌单形式,用户进入的是同一份歌单,但实际上每个用户看到的歌曲内容都不一样。本质也是个性化推荐功能。

我让平时日均听歌时间超过 2h 的哥们试用了下,他表达说,感觉私人雷达的准确度还不错,让他有兴趣收藏的会在 1/2,用其它产品类似功能的时候一般到 1/4 就不错了。
和其他推荐功能不同,歌单是可以评论的,在工具性的基础上还有点社区互动属性。私人雷达的评论区是这样的:
有个细节是,私人雷达会出现听过的歌,因此更像心动模式(基于红心歌曲进行推荐的模式)。说明是与“发现新歌”不同的场景。
这就很有意思了。是否对更多场景,有更多个性化探索的可能性?现在的场景化大都是 UGC 来完成,未来是否有针对每个人个性化的咖啡场景动态歌单、学习场景动态歌单?
UGC+机器学习算法结合,在音乐曲库方面,会比文字和视频都要容易做(歌曲的信息更机构化),也许是一个很前瞻的探索。
先说到这吧,希望能有启发。
本文(含图片)为合作媒体授权创业邦转载,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







