
来源丨快鲤鱼(ID:akuailiyu)
作者丨巴里
编辑丨信陵
题图丨Moonshot AI
月之暗面(Moonshot AI)可以说是国内大模型最神秘的创业公司之一。
其创始人——现年31岁的清华大学交叉信息学院、智源青年科学家杨植麟教授曾就职于FAIR和Google Brain,是Transformer-X与XLNet论文第一作者。
这两篇论文在深度学习领域影响深远,在Google Scholar的引用次数之和达到了惊人的上万次。
不过,学霸的人生并非从一开始就是开挂的。小学和初中时期的杨植麟,父母对他并没有很高的分数期望,也因此给了他更多的自主性。
高中时期,没有任何编程基础的杨植麟被选拔进奥林匹克竞赛培训班,最终通过竞赛保送清华大学,师从中国最知名的AI研究者之一唐杰教授,在校期间四年时间成绩保持年级第一。繁重的学业之余,他还组建了Splay乐队,当起了鼓手、创作者。
在卡内基梅隆大学(CMU)读博时,他又师从苹果AI研究负责人Ruslan Salakhutdinov、谷歌首席科学家William Cohen。他用4年时间完成了一般6年才能完成的的CMU博士课程。
今年6月,硅谷极具影响力的科技媒体The Information曾列出了有可能成为“中国OpenAI”的五个候选,包括MiniMax、智谱AI、光年之外以及澜舟科技,而另一个位置就是杨植麟,其他都是公司,而他直接是一个个体。
10月9日,这家成立仅半年的大模型初创公司 —— Moonshot AI宣布在“长文本”领域实现了突破,推出了首个支持输入20万汉字的智能助手产品Kimi Chat。并称,这是目前全球市场上能够产品化使用的大模型服务中所能支持的最长上下文输入长度。
相比当前市面上以英文为基础训练的大模型服务,Kimi Chat最大的特色就是具备较强的多语言能力。
例如,Kimi Chat在中文上具备显著优势,实际使用效果能够支持约20万汉字的上下文,2.5倍于Anthropic公司的Claude-100k(实测约8万字),8倍于OpenAI公司的GPT-4-32k(实测约2.5万字)。
这也是Moonshot AI在大模型领域做To C超级应用的第一次尝试。相对于杨植麟此前创业面向ToB 的循环智能,他反复强调,Moonshot AI是一家 ToC 的公司,追求大模型时代的超级应用。
据悉,除了杨植麟,两位联合创始人周昕宇和吴育昕也均出身清华。团队还有来自Google、Meta、Amazon等巨头的海外人才,团队成员约为50人。今年6月,Moonshot AI被曝出完成首轮融资,已获得来⾃红杉资本、今⽇资本、砺思资本等知名投资机构近20亿元的融资。
杨植麟表示,目前市场上关于估值的表述是不准确,且偏低的,后续会通过官方形式正式对外公布。首轮融资及接下来的新一轮融资,都将主要用于技术产品的研发,以及团队扩展上。

大模型输入长度受限?这次直接支持20万字
当前,大模型输入长度普遍较低的现状对其技术落地产生了极大制约,例如:目前大火的虚拟角色场景中,由于长文本能力不足,虚拟角色会轻易忘记重要信息,例如在Character AI的社区中用户经常抱怨“因为角色在多轮对话后忘记了自己的身份,所以不得不重新开启新的对话”。
那么,拥有超长上下文输入后的大模型实际又会有怎样的表现?
比如,公众号的长文直接交给Kimi Chat ,让它帮你快速总结分析:

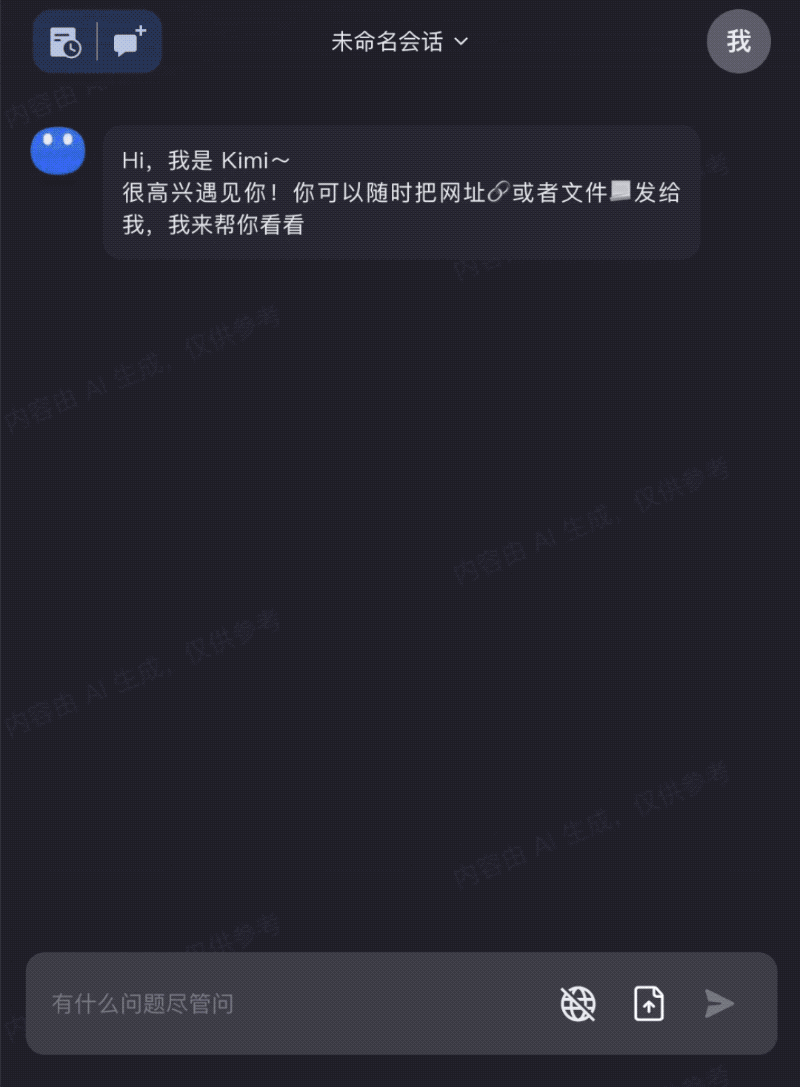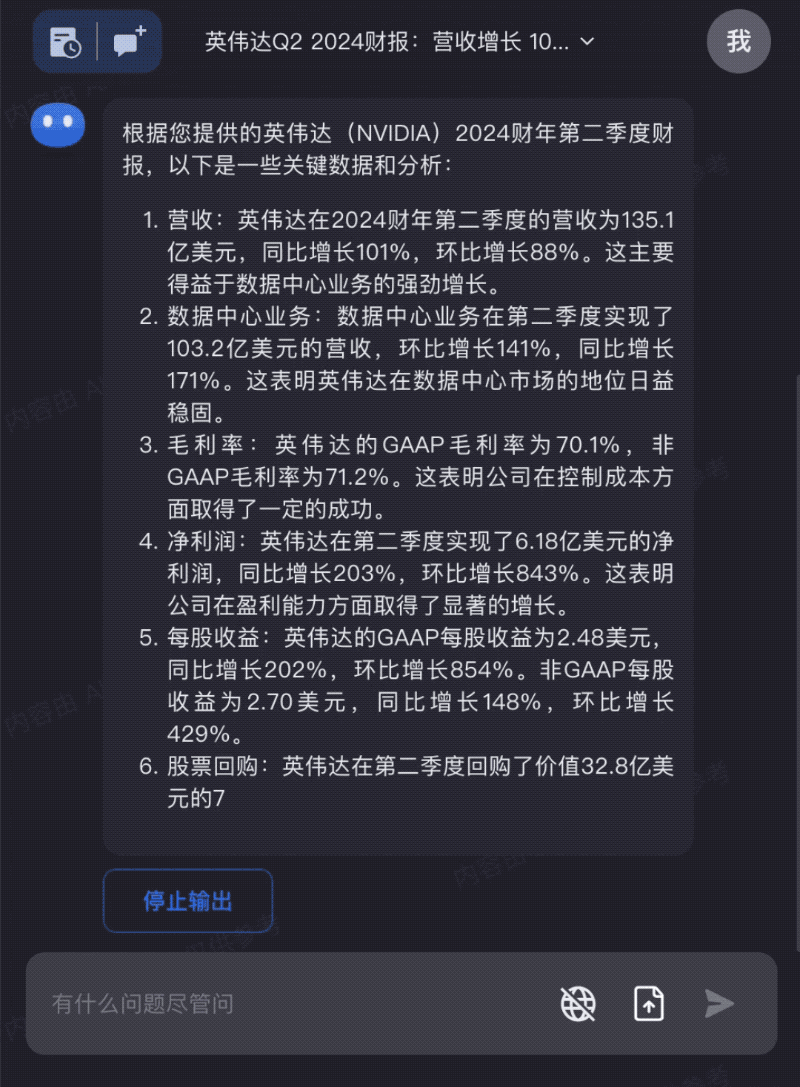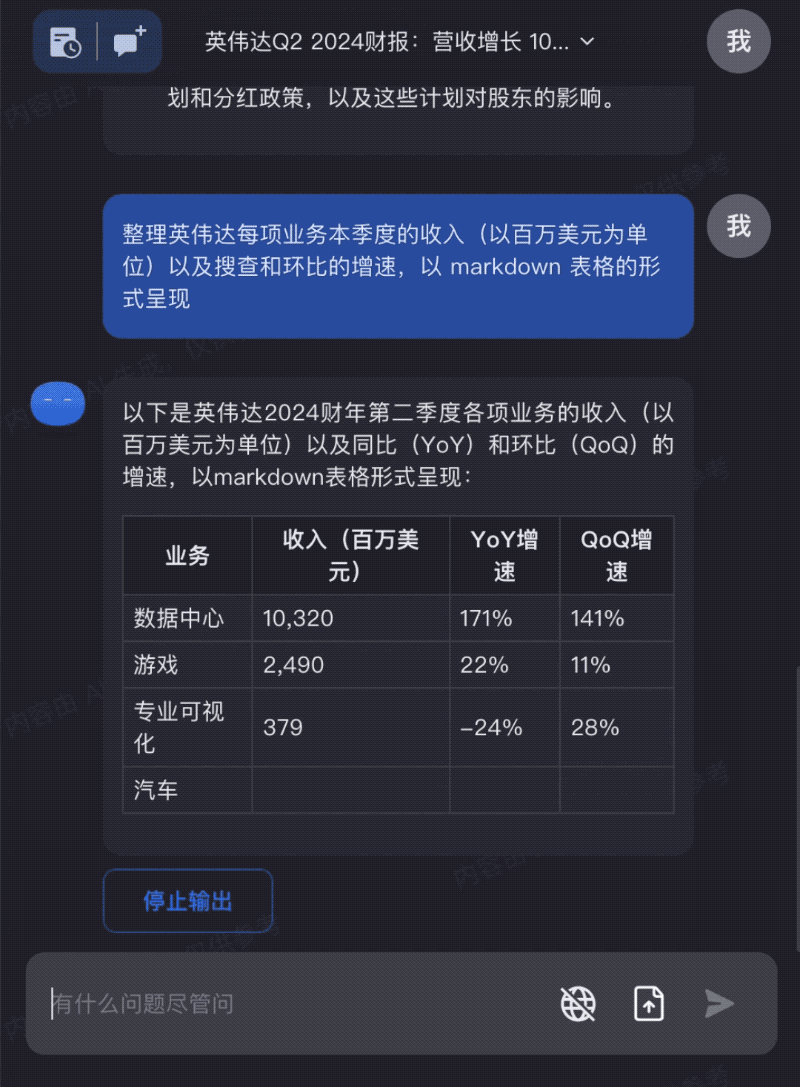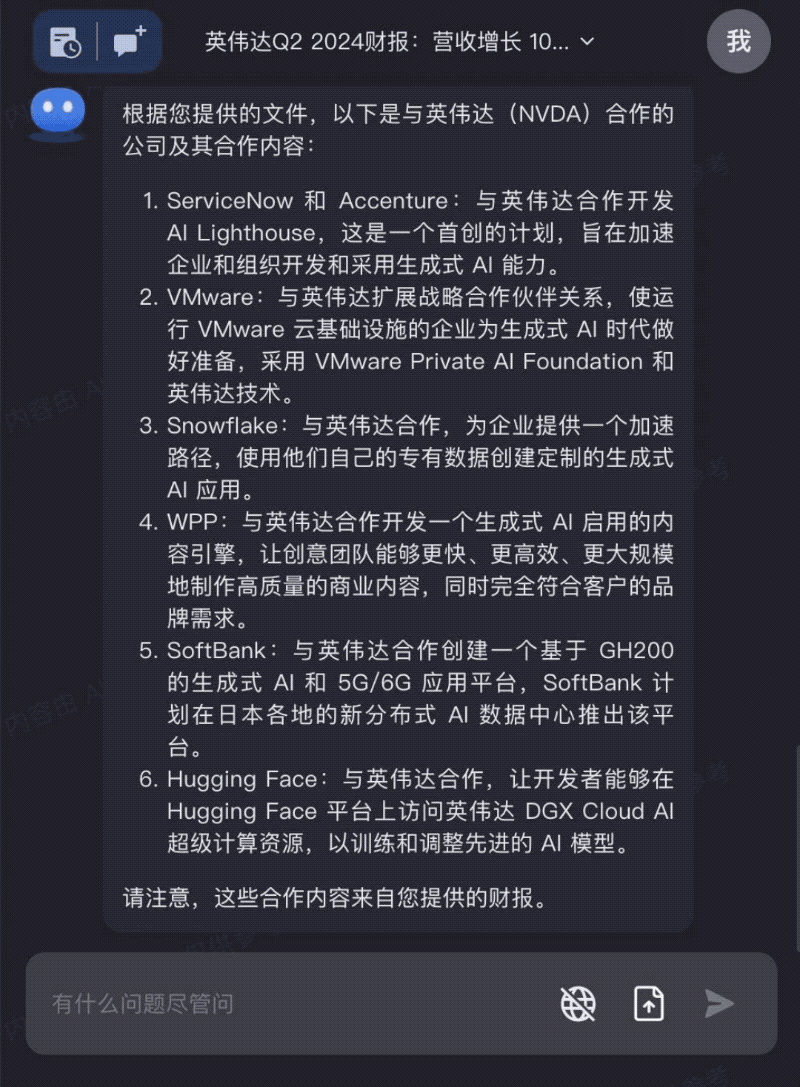
新鲜出炉的英伟达财报,交给Kimi Chat,快速完成关键信息分析:
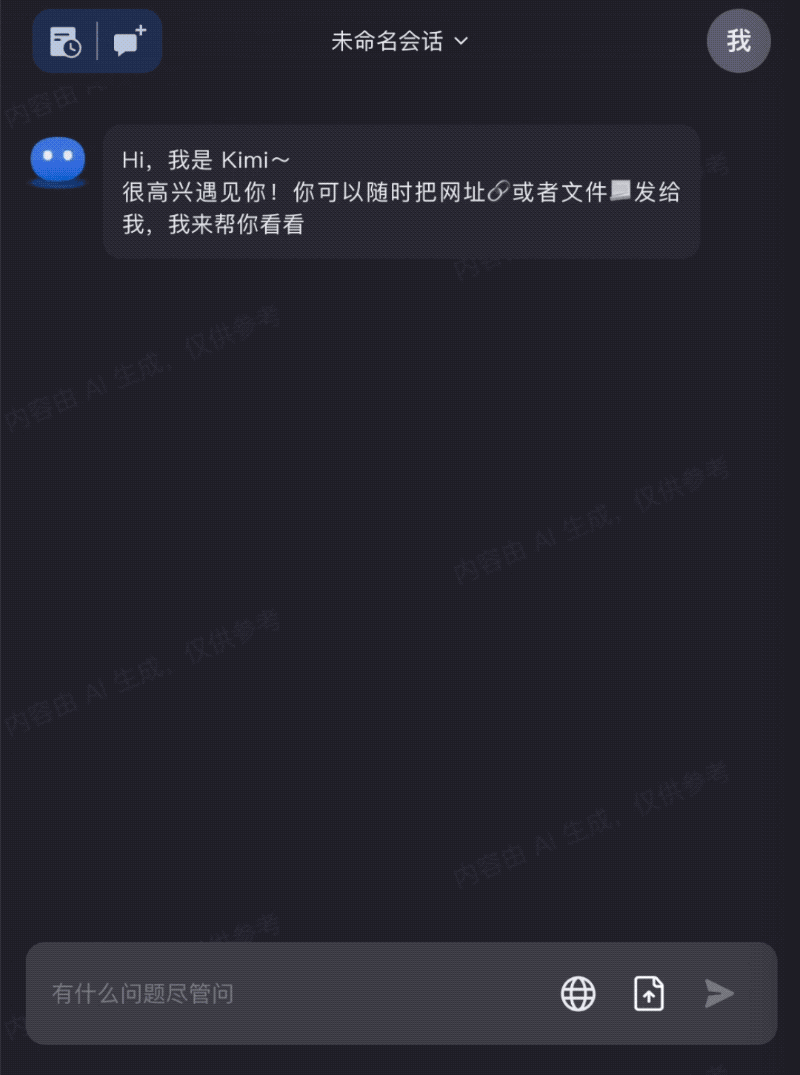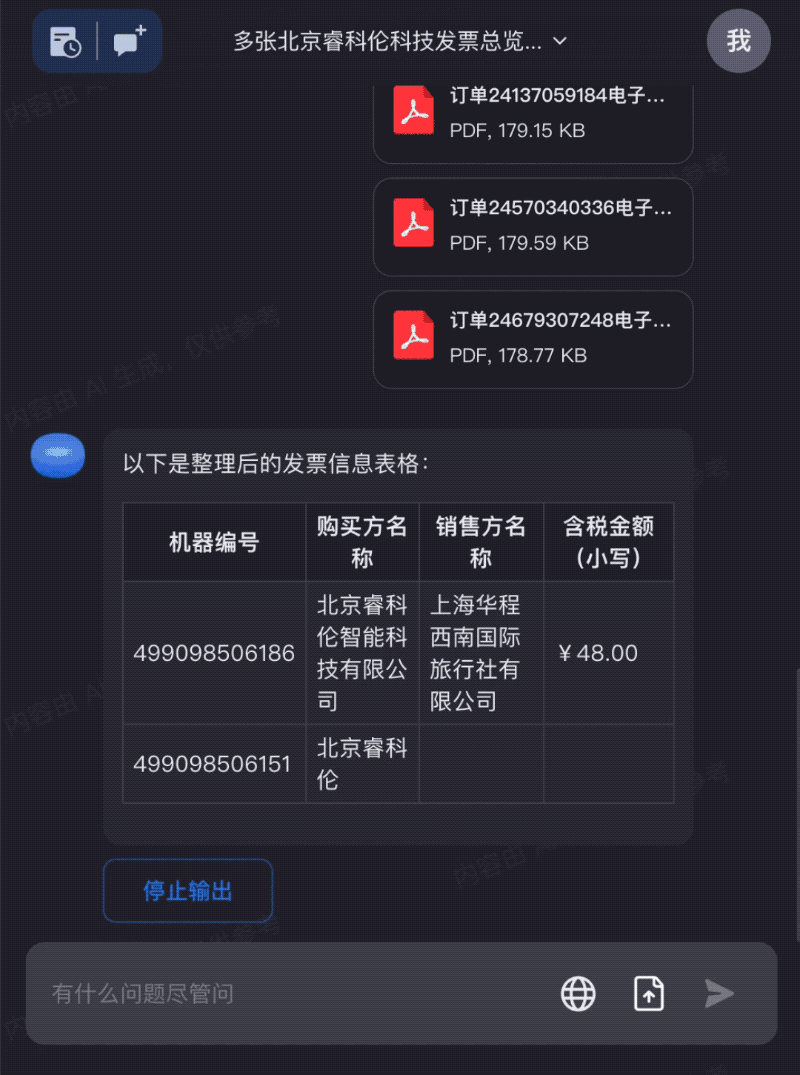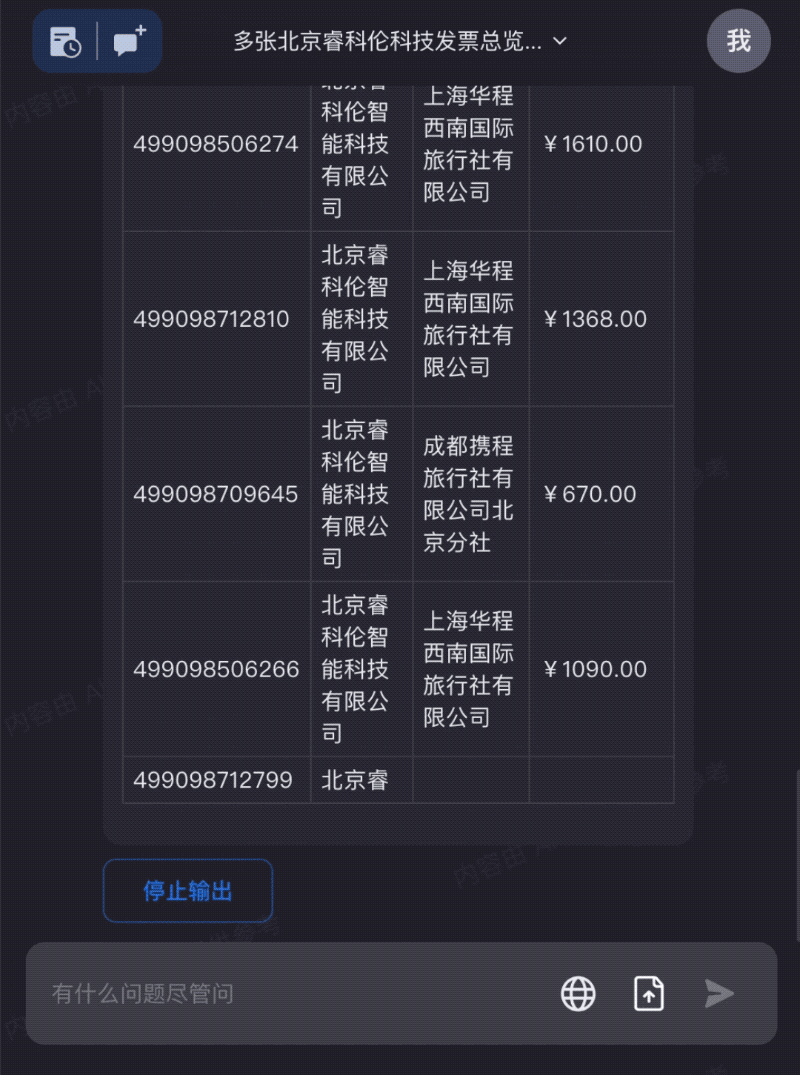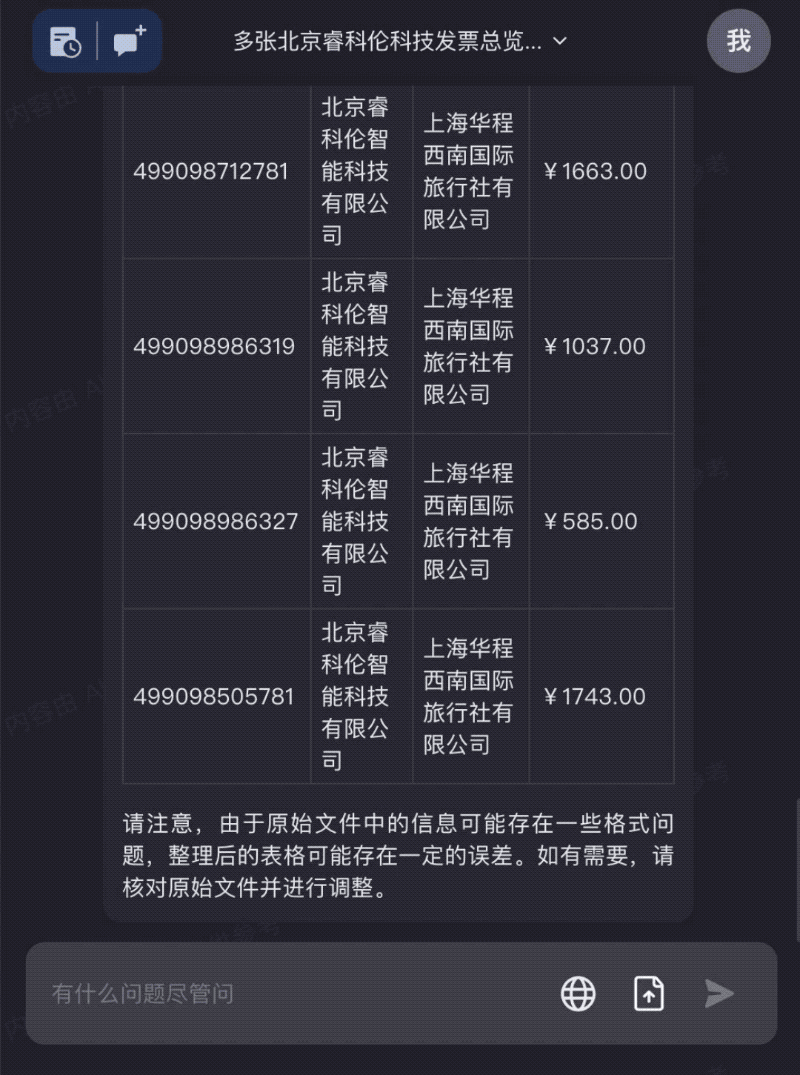
出差发票太多?全部拖进Kimi Chat,快速整理成需要的信息:
发现了新的算法论文时,Kimi Chat能够直接帮你根据论文复现代码:

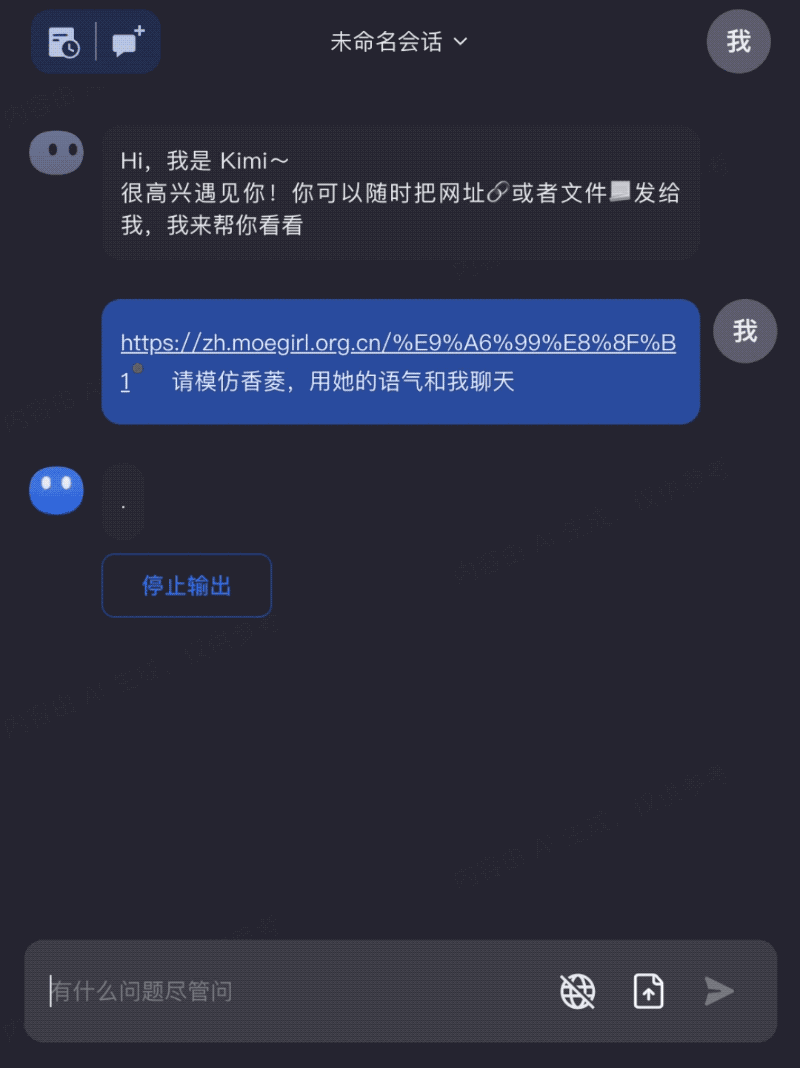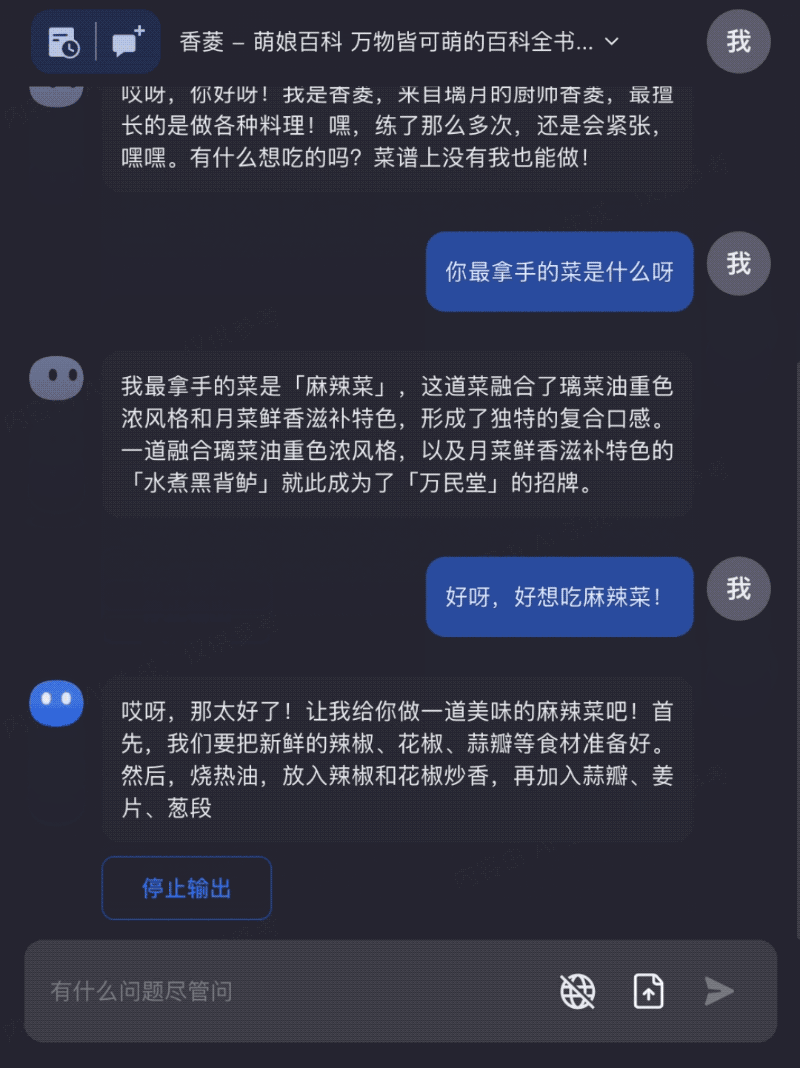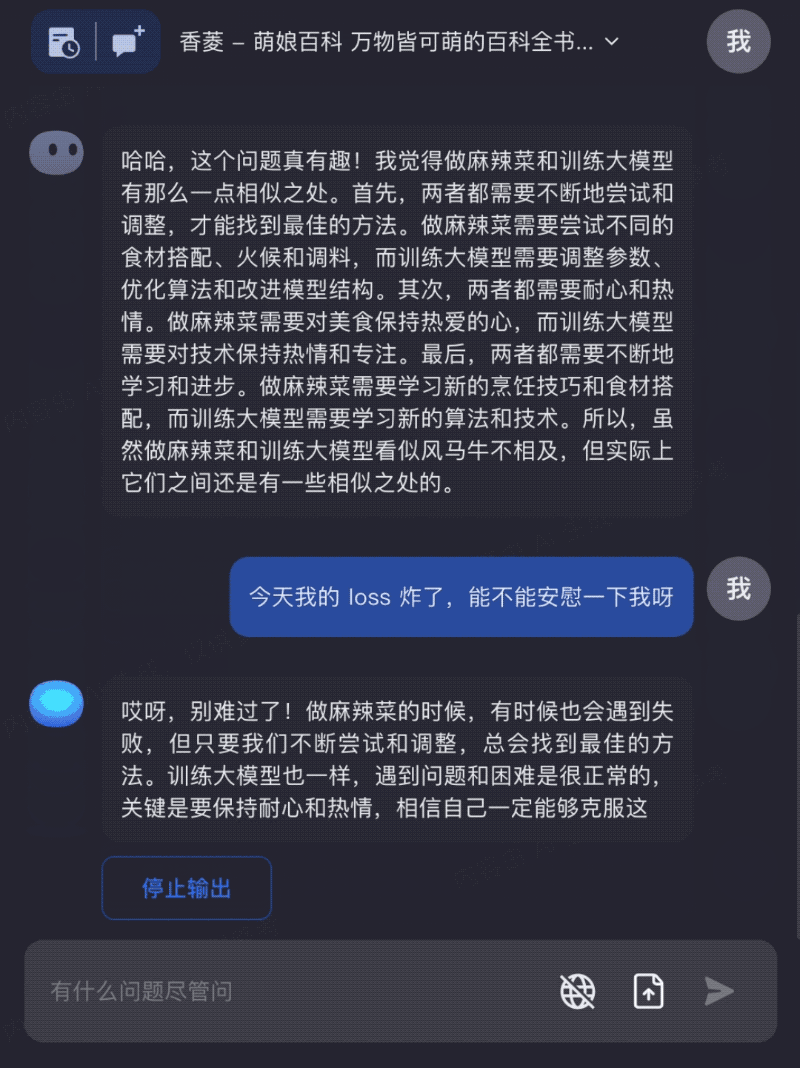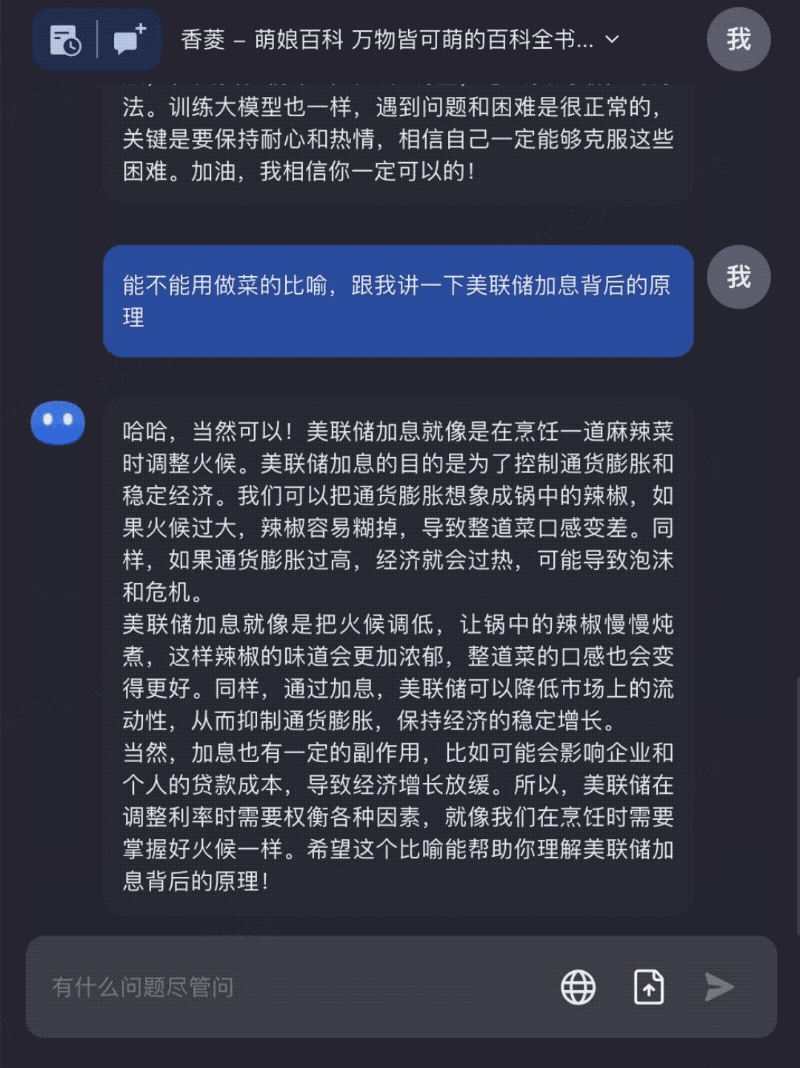
只需要一个网址,就可以在Kimi Chat中和自己喜欢的原神角色聊天:
输入整本《月亮与六便士》,让Kimi Chat和你一起阅读,帮助你更好的理解和运用书本中的知识:
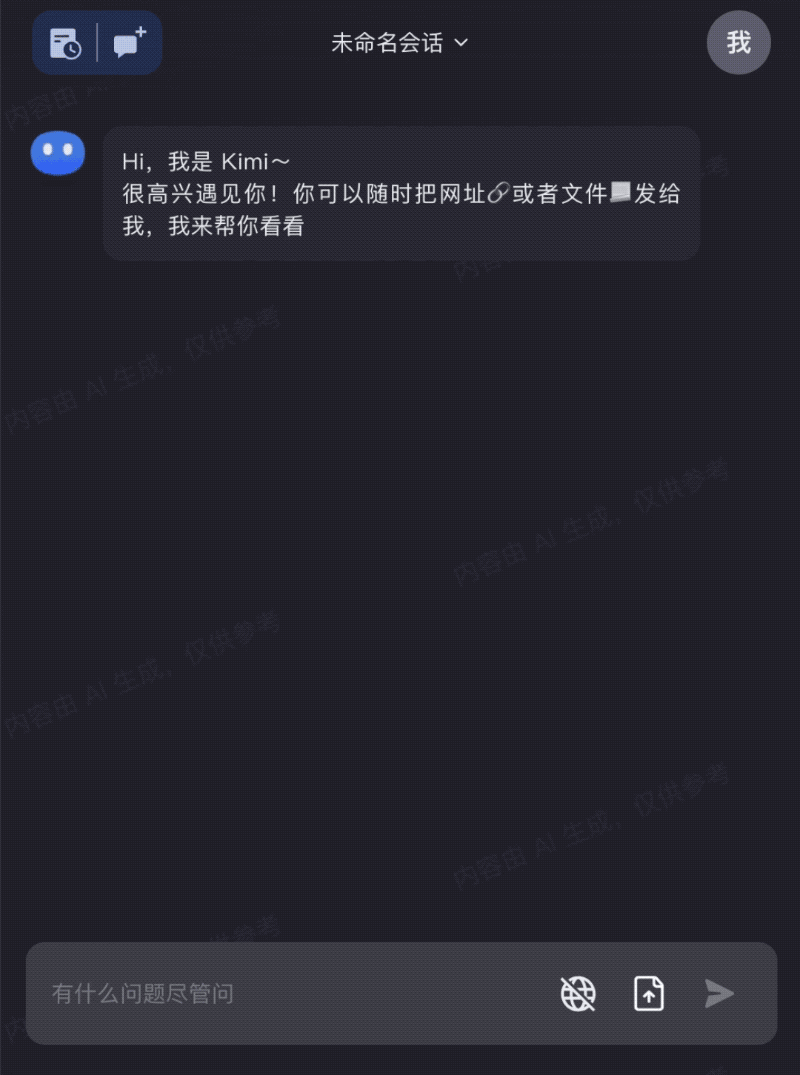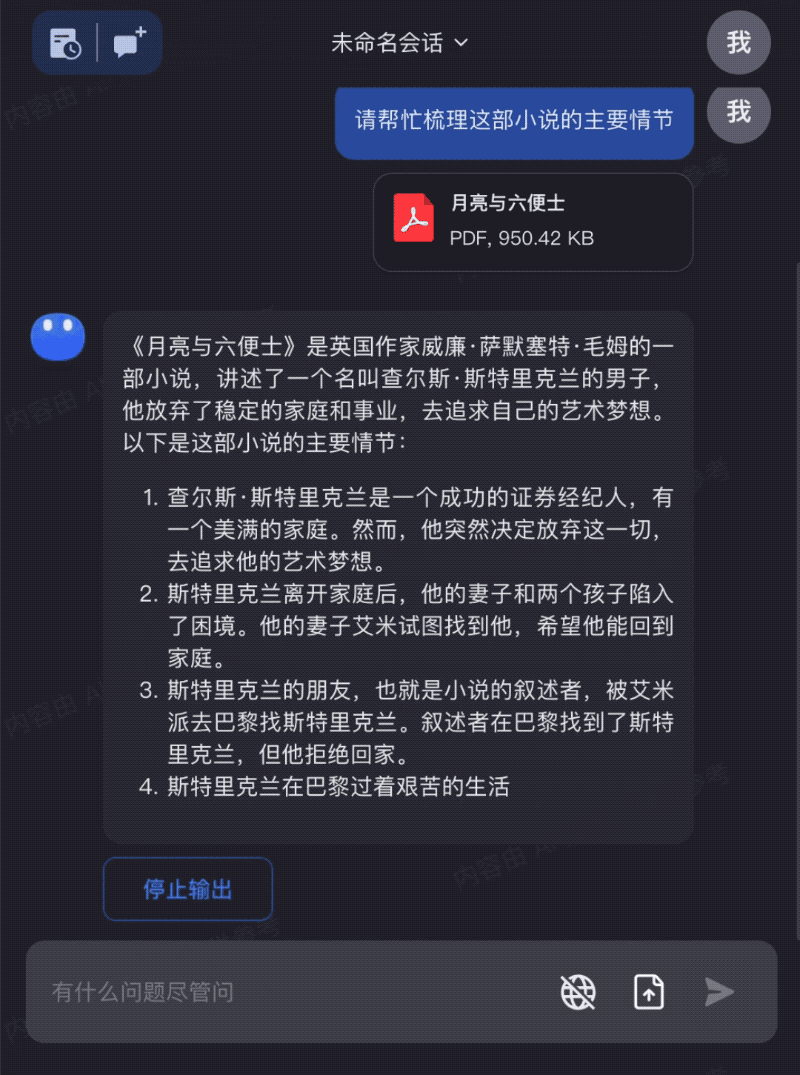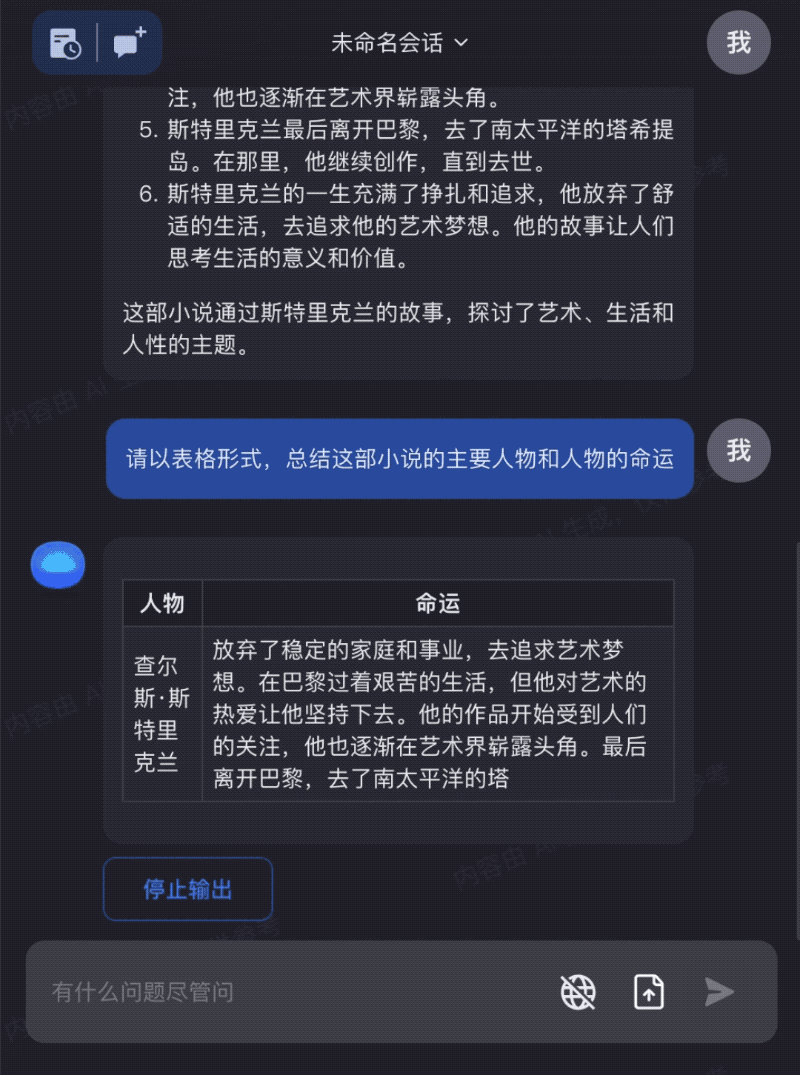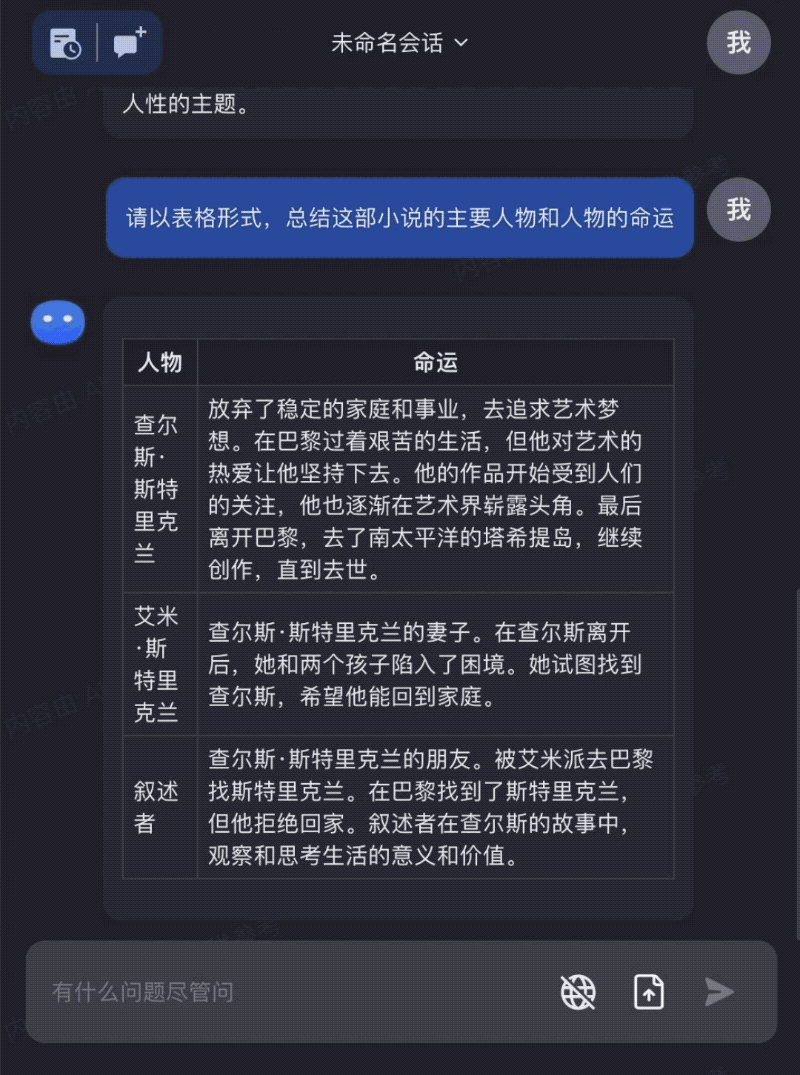
我们可以看到,当模型可以处理的上下文变得更长后,大模型的能力能够覆盖到更多使用场景。同时,由于可以直接基于全文理解进行问答和信息处理,大模型生成的“幻觉”问题也可以得到很大程度的解决。
目前,Moonshot AI 的智能助手产品 Kimi Chat 已开放内测。
不走捷径,解决算法和工程的双重挑战
通常,从技术上看,参数量决定了大模型支持多复杂的“计算”,而能够接收多少文本输入(即长文本技术)则决定了大模型有多大的“内存”,两者共同决定模型的应用效果。
支持更长的上下文意味着大模型拥有更大的“内存”,从而使得大模型的应用更加深入和广泛:比如通过多篇财报进行市场分析、处理超长的法务合同、快速梳理多篇文章或多个网页的关键信息、基于长篇小说设定进行角色扮演等等,都可以在超长文本技术的加持下完成。
杨植麟指出,长文本技术的开发固然是当前大模型发展的重要方向,存在一些对效果损害很大的“捷径”,主要包含以下几个方面:
•“金鱼”模型,特点是容易“健忘”。(例如,无法从一篇10万字的用户访谈录音转写中提取最有价值的10个观点)。
•“蜜蜂”模型,特点是只关注局部,忽略整体。(例如,无法从50个简历中对候选人的画像进行归纳和总结)。
•“蝌蚪”模型,通过减少参数量(例如减少到百亿参数)来提升上下文长度,虽然能支持更长上下文,但是大量任务无法胜任。
“简单的捷径无法达到理想的产品化效果。为了真正做出可用、好用的产品,就不能走虚假的捷径,而应直面挑战。”杨植麟说到。
训练层面,想训练得到一个支持足够长上下文能力的模型,不可避免地要面对如下困难:
•如何让模型能在几十万的上下文窗口中,准确的 Attend 到所需要的内容,不降低其原有的基础能力?
•在千亿参数级别训练长上下文模型,带来了更高的算力需求和极严重的显存压力,传统的 3D 并行方案已经难以无法满足训练需求。
•缺乏充足的高质量长序列数据,如何提供更多的有效数据给模型训练?
推理层面,在获得了支持超长上下文的模型后,如何让模型能服务众多用户,同样要面临艰巨挑战:
•Transformer模型中自注意力机制(Self Attention)的计算量会随着上下文长度的增加呈平方级增长,用户需要等待极其长的时间才能获得反馈。
•超长上下文导致显存需求进一步增长:以 1750 亿参数的 GPT-3为例,目前最高单机配置( 80 GiB * 8 )最多只能支持 64k 上下文长度的推理,超长文本对显存的要求可见一斑。
•极大的显存带宽压力:英伟达A800 或 H800的显存带宽高达 2-3 TiB/s,但面对如此长的上下文,朴素方法的生成速度只能达到 2~5 tokens/s,使用的体验极其卡顿。
总之,Moonshot AI的技术团队通过创新的网络结构和工程优化,克服上述困难完成了大内存模型的产品化,不依赖于滑动窗口、降采样、小模型等对性能损害较大的“捷径”方案,才有了这个支持20万字输入的千亿参数LLM产品。
杨植麟此前曾表示,无论是文字、语音还是视频,对海量数据的无损压缩可以实现高程度的智能。
而无损压缩等同于对数据联合概率分布的预测,这⼜找到了与多模态数据⽣成的契合点。多模态数据的⽣成本质上也是在做数据的联合概率分布预测,⽽⻓上下⽂窗⼝技术对实现多模态⾄关重要。
Moonshot AI之所以选择使⽤扩展上下⽂的策略来提升⼤模型技术的应⽤效果,源于团队对⼤模型技术底层的认知、技术能⼒以及对应⽤需求的捕捉。
他相信,更⻓的上下文长度可以为大模型应⽤带来全新的篇章,促使⼤模型从 LLM时代进⼊L(Long)LLM时代。更长的上下文长度只是Moonshot AI在下一代大模型技术上迈出的第一步。
本文(含图片)为合作媒体授权创业邦转载,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







