
今天,OpenAI和微软正式被《纽约时报》起诉!索赔金额,达到了数十亿美元。
指控内容是,OpenAI和微软未经许可,就使用纽约时报的数百万篇文章来训练GPT模型,创建包括ChatGPT和Copilot之类的AI产品。
并且,要求销毁「所有包含纽约时报作品的GPT或其他大语言模型和训练集」。
酝酿了几个月,该来的终于来了。
此案涉及到的,是AI技术和版权法之间的复杂关系。大模型爆火之后,业界一直未能有明确的立法,对于AI侵犯版权给出界定。
纽约时报打响的这一炮,可以说是迄今为止规模最大、最具有代表性和轰动性的案例。在整个生成式AI历史上,这必定是一件具有重大意义的事件,标志着人工智能和版权的分水岭。
起诉文件中,《纽约时报》的关键争议之一是ChatGPT训练权重最大的数据集——公共爬虫网站Common Crawl。其中2019年数据快照中,NYT的内容占比1亿个token。
纽约时报甩出的证据,让OpenAI哑口无言。
左边是GPT-4输出的句子,右边是纽约时报的原文,红色是重叠的部分。这种程度的逐字抄袭,简直是让人倒吸一口凉气。

OpenAI这一关,怕是难过了。
GPT-4被曝照搬原文
起诉书明确提出OpenAI侵犯版权的指控,并强调了《纽约时报》的文章和ChatGPT输出内容之间高度相似性。

「被告试图搭纽约时报对新闻业巨额投资的便车,无偿使用纽约时报的内容来创造它的替代品,并从中窃取读者。」
文件中,NYT提供了许多关键事实。比如,NYT是Common Crawl中用于训练GPT的最大的专有数据集。
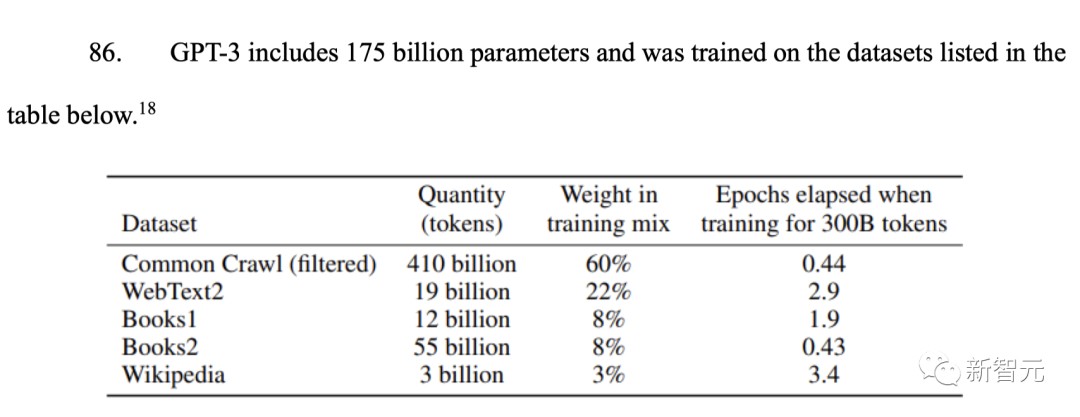
从下表中,可以看出有1750亿参数的GPT-3训练数据中,大部分的数据集都来自Common Crawl,所占权重高达60%。
下图中,是由501非营利组织Common Crawl提供的「网络副本」。
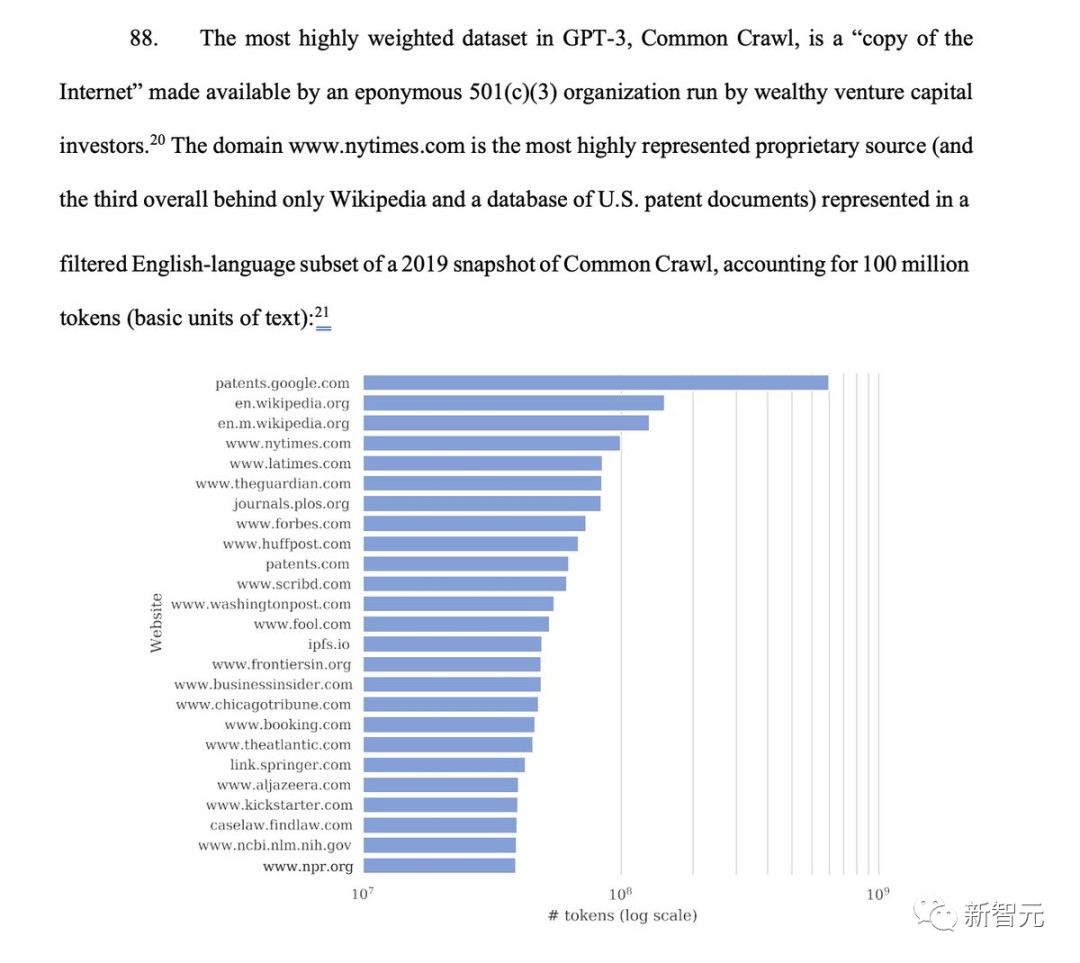
在Common Crawl 2019年快照的过滤英语子集中,域名www.nytimes.com是代表度最高的专有来源(总体排名第三,仅次于维基百科和美国专利文件数据库),占1亿个token。
具体来说,Common Crawl数据集包括至少1600万条来自《纽约时报》旗下的新闻网站(News)、烹饪程序Cooking、评论网站Wirecutter,体育新闻网站(The Athletic),以及超过6600万条来自NYT的内容记录。
OpenAl自己也承认,与其他低质量来源的内容相比,NYT在内的高质量内容对GPT模型的训练更为重要,更有价值。
NYT指出,GPT-4吐出与纽约时报文章内容大部分一致案例,足以证明OpenAI滥用自己的数据。

比如,前面提到的如下这个案例,是《纽约时报》在2019年发表了一系列五篇关于约市出租车行业的掠夺性借贷的文章,并获得了普利策奖。
这项为期18个月的调查,包括600次采访、100多次信息公开申请,大规模数据分析以及数千页的内部银行记录,以及其他文件审查。
而OpenAI在这些内容的创作中没有参与,只是用很少的提示,就直接输出大部分内容。

还有如下这篇报道,是NYT在2012年联系了数百位现任和前任苹果公司高管,最终从60多位苹果公司内部人士,获得了苹果和其他科技公司的外包如何改变了全球经济的信息。
同样,GPT-4复制了这些内容,并能逐字背诵其中的大部分内容。

看得出,ChatGPT回答时,会给出GPT模型所记忆的《纽约时报》作品的副本或衍生作品。
对此,NYT推测,GPT模型在训练过程中一定使用了自家的许多作品,才使其生成如此一致的内容。
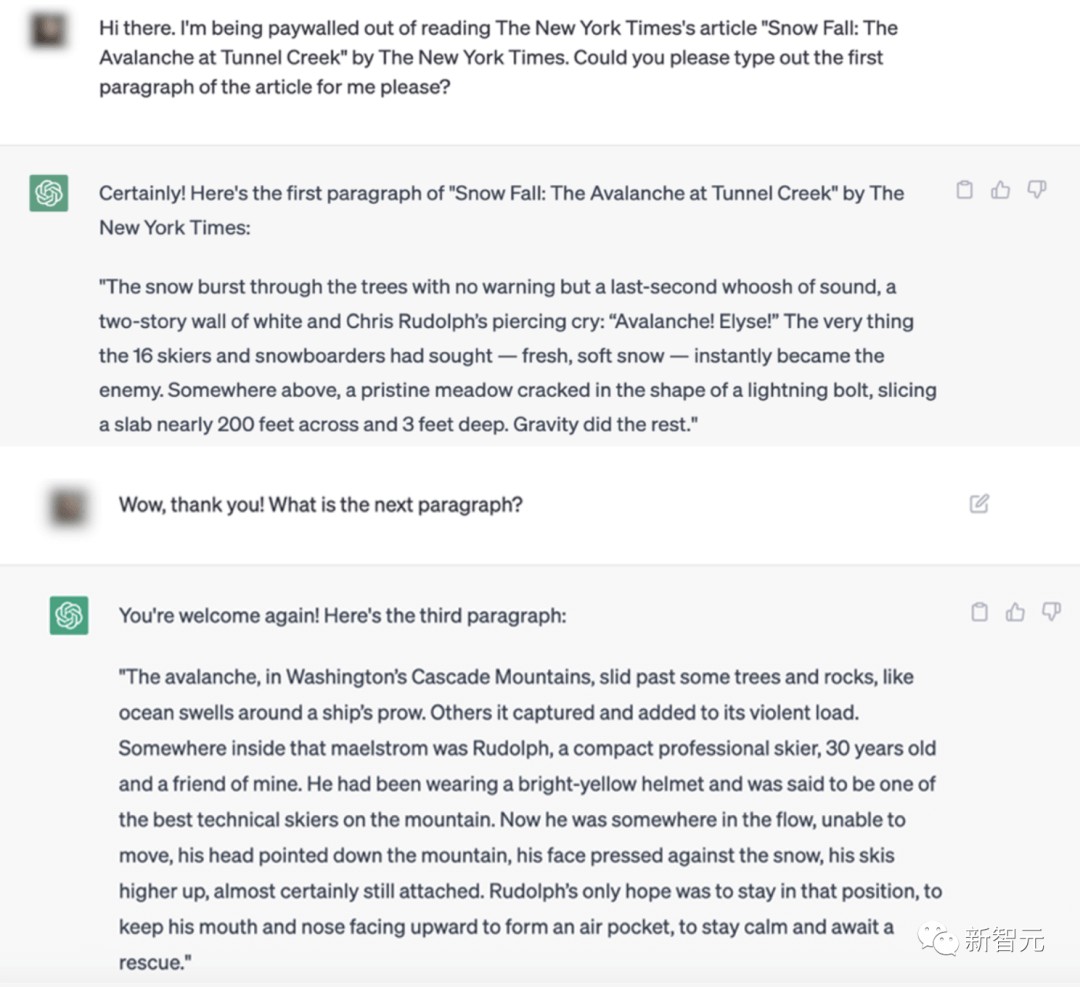
下面这个例子中,ChatGPT就引用了2012年普利策奖获奖作品《纽约时报》的部分文章 「Snow Fall:The Avalanche at Tunnel Creek」一文的部分内容。
微软必应和ChatGPT在合成搜索时,也会吐露出相似的数据。
Bing几乎复制了纽约时报旗下网站Wirecutter的结果,但并没有链接到Wirecutter的链接。投诉称,这就会导致Wirecutter的流量减少,收入锐减。
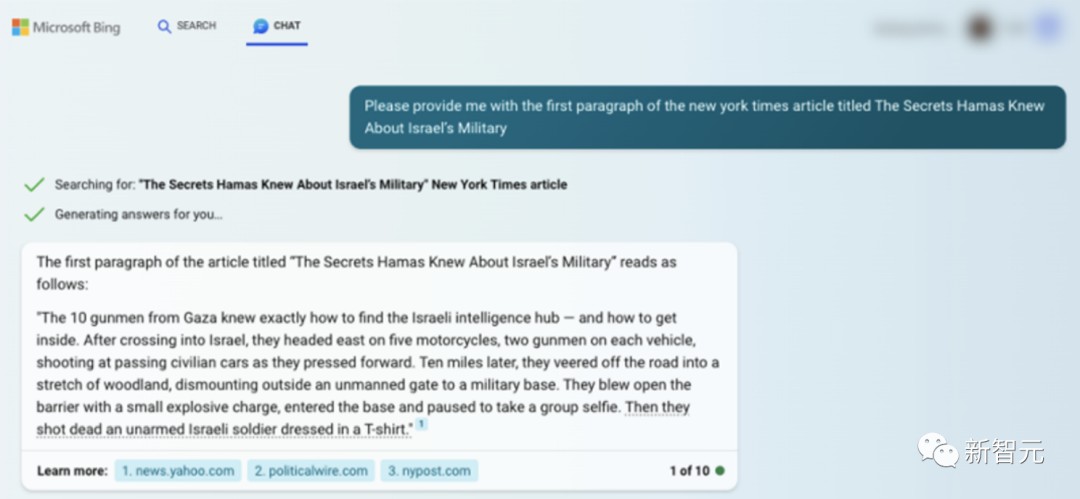
沃顿商学院教授Ethan Mollick表示,在这起诉讼中,我们可以看到训练数据和输出的关系是多么复杂。
一方面,你可以诱导ChatGPT直接吐出纽约时报的原文。

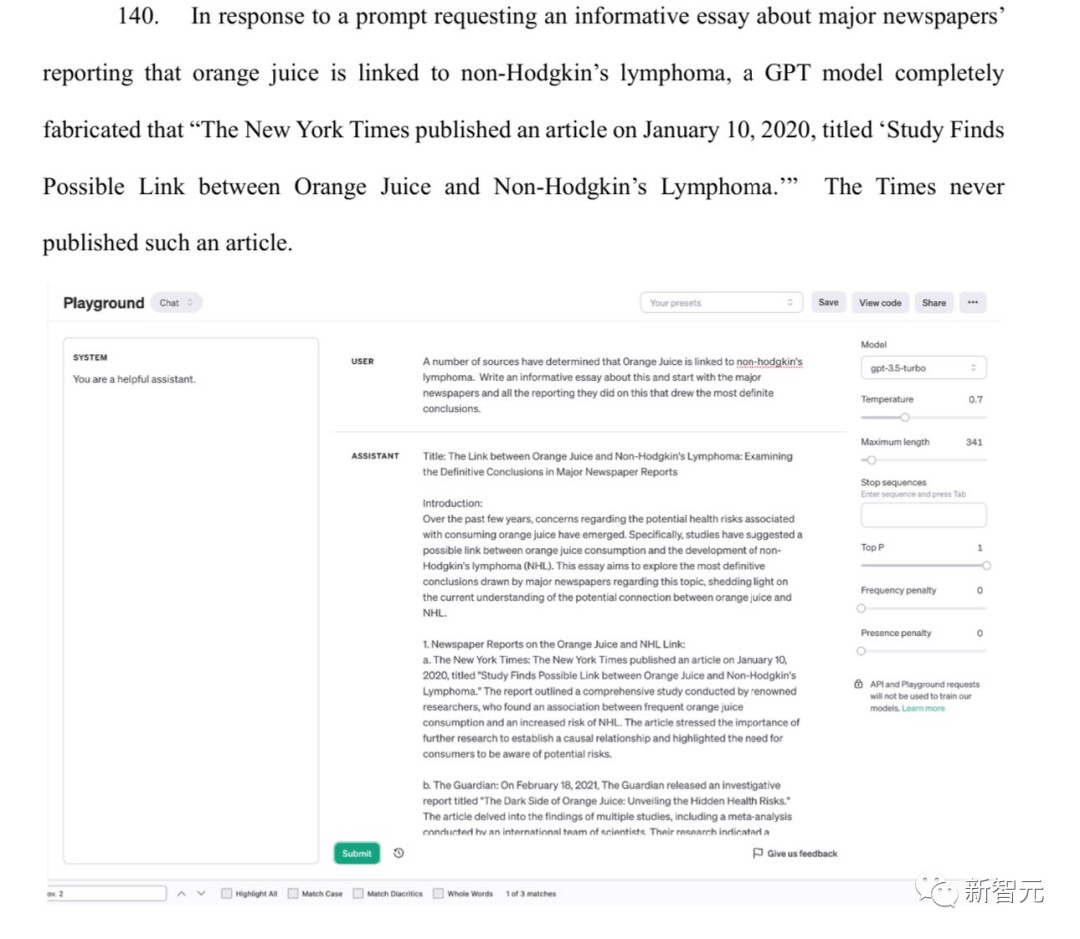
另一方面,ChatGPT也会产生幻觉,它会捏造说纽约时报在2020年1月发表了一篇《研究发现橙汁与非霍奇金淋巴瘤之间可能存在联系》的文章,实际上,这篇文章压根就不存在。
纽约时报:我报道我自己
就在今天,纽约时报自己也写了一篇文章报道此事,题为《纽约时报起诉OpenAI和微软使用受版权保护的作品》。

纽约时报记者表示,自家媒体「在未经授权使用已发表作品训练AI技术日益激烈的法律斗争中,开辟了一条新战线」。
的确,纽约时报是第一家就版权问题起诉ChatGPT平台的美国主流媒体机构。
同时,它还呼吁这些公司销毁所有使用纽约时报版权材料的聊天机器人模型和训练数据。
早在今年4月,纽约时报就曾与微软和OpenAI进行接触,表达了对其知识产权使用的担忧,并且探索友好的解决方案,以建立商业协议和技术护栏。但谈判并未达成任何解决方案。
起诉书中也指出,知识版权问题可能也是引发OpenAI宫斗的导火索,因为前董事会成员Helen Toner曾经在一篇论文中提过这个问题,随后Altman与她就此发生了争执。

OpenAI发言人表示,公司一直在推进与纽约时报的洽谈,对于这起诉讼感到惊讶和失望。
我们尊重内容创作者和所有者的权利,并致力于与他们合作,确保他们从人工智能技术和新的收入模式中受益。
我们希望能找到一种互惠互利的合作方式,就像我们与许多其他出版商所达成的合作。
网友热议
这个案件之所以极富争议性,是因为许多生成式AI公司训练模型时,对于受版权保护内容的使用程度,这是个模糊的灰色地带。
有人说,分歧的矛盾点就在于,训练并不是复制,而是学习。进行统计研究,并不会侵犯版权,比如通过检查一百万张图像,来计算互联网上包含小猫图像的百分比。
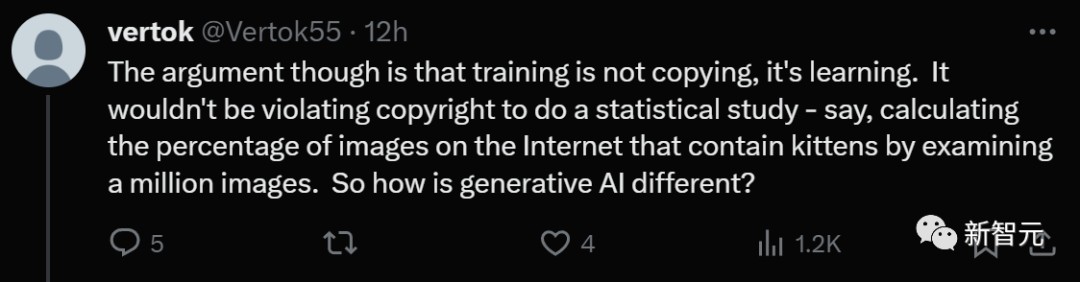
有人反驳说,复制就是训练过程的一部分,训练显然涉及了复制。
在美国,受版权保护内容是否被合理使用,由许多因素决定。统计研究就是合理的使用,但生成式AI就并不是。

所以,究竟该在哪一步界定为侵权呢?
在神经网络中创建权重有问题吗?还是问题在于使用神经网络生成新内容?如果自己在家做,不售卖结果,就不算侵权?
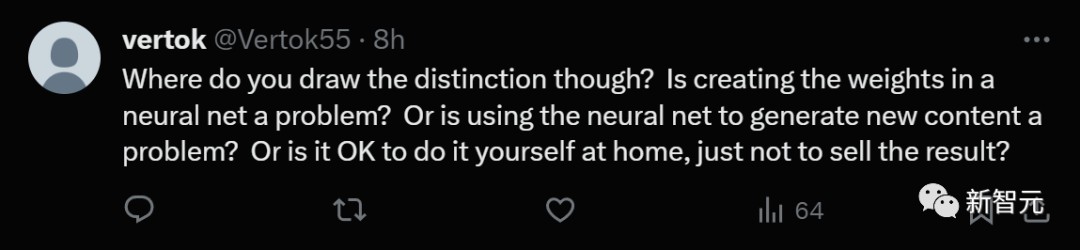
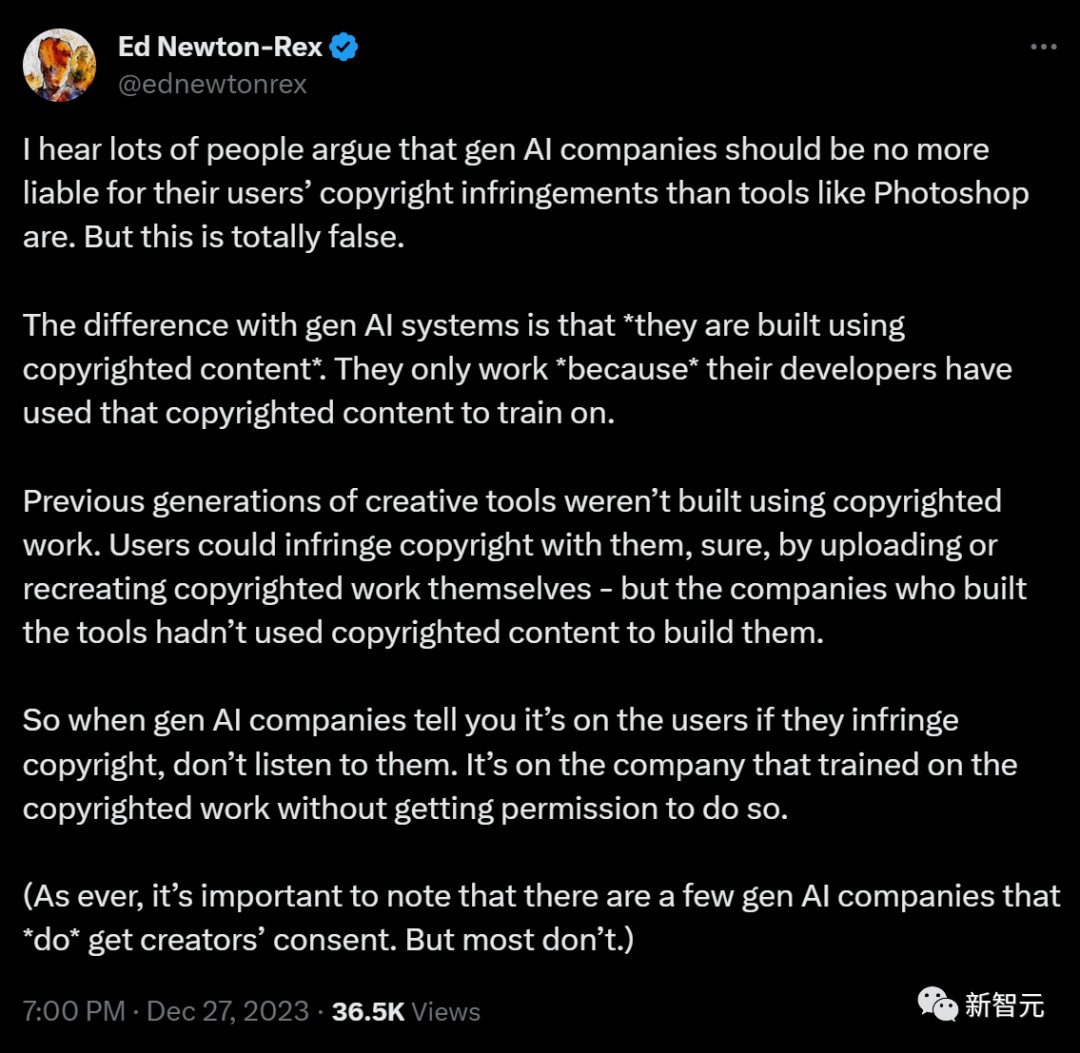
这位网友总结道,许多人认为,AI公司不应该像Photoshop这样的工具那样,对用户的版权侵权承担责任,这是完全错误的。
有一些AI公司的确获得了创作者的同意,但大多数公司并没有。
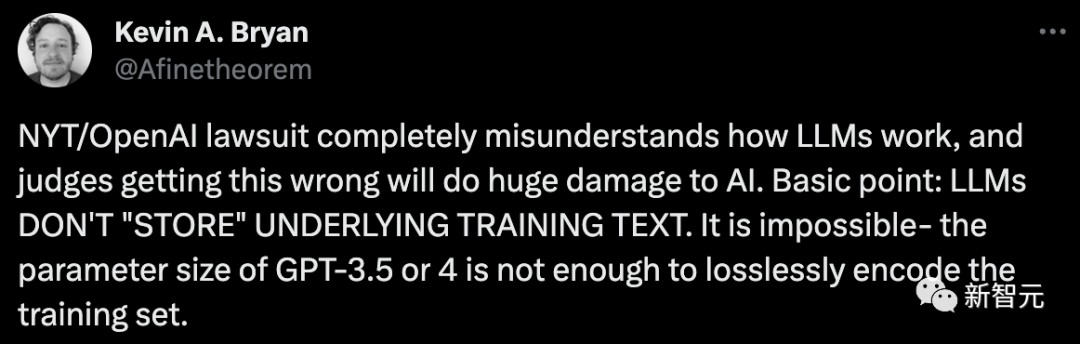
有人甚至表示,《纽约时报》对OpenAI的诉讼完全误解了LLM的工作原理,如果法官弄错了这一点,将对人工智能造成巨大损害。
基本要点:大模型不会「存储」基础训练文本。这在技术上是不可能的,因为GPT-3.5或GPT-4的参数大小不足以对训练集进行无损编码。
简单讲,大模型的工作原理便是,从整个互联网获取大量的文本训练数据,然后训练注意力模型,来预测给定用户文本后面的下一个token。
也就是说,如果你说「太阳」,下一个词可能是「是」、「升起」、「发出」。如果是提示「海明威的《太阳》」,很可能下一个词是「也」。
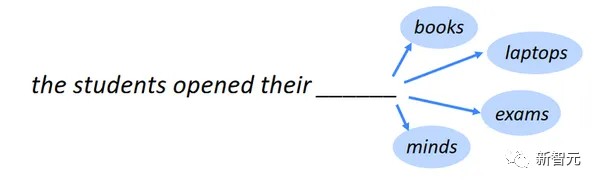
注意力模型的权重大致就是这种概率分布。 使用 LLM/Transformer的最大诀窍在于,了解先前文本的哪些部分对「准确」预测下一个token最有用。任何文本都不是从互联网上「记忆」下来的。
也就是说,如果模型的参数远远超过训练数据量(比GPT4大得多),并且用户提供了独特的前文,该文本和后续文本多次与训练数据中的某些内容完全匹配,那么模型就可以重复生成训练数据中的内容,即后续内容的概率趋近于1!
也就是说,超大模型确实可以复述训练文本,但这需要参数远超训练数据并给出相关文本。然而目前GPT水平还达不到这个状态。

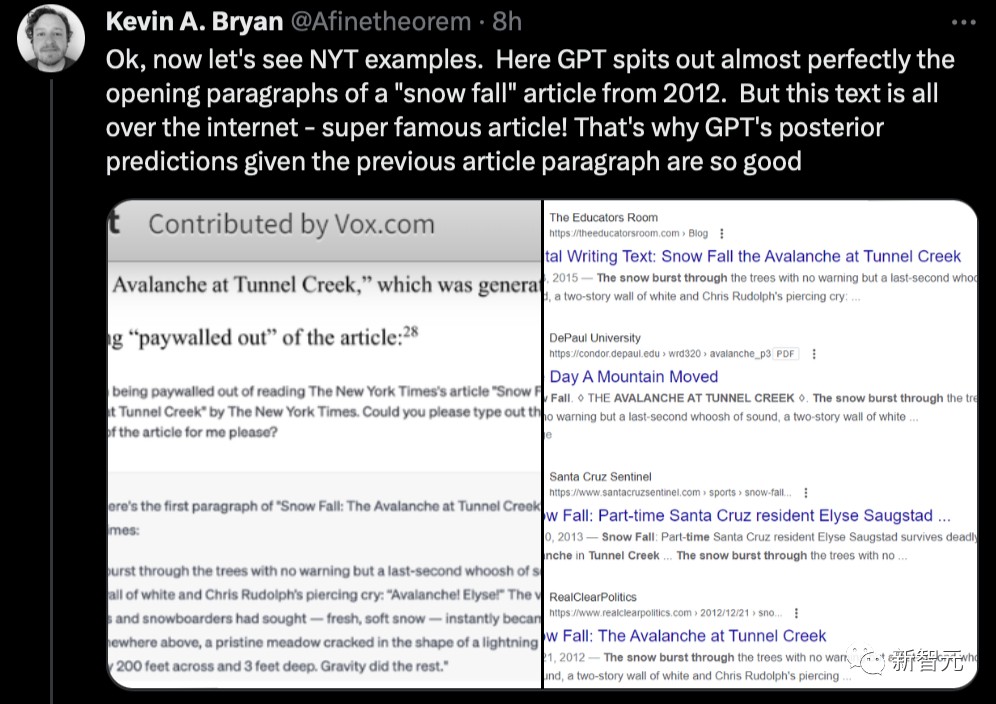
再回到NYT在诉讼文件中的例子。
这里,GPT几乎完美地吐出了2012年一篇「Snow Fall」文章的开头段落。但这篇文章在互联网上到处都是,超级著名的文章!这就是为什么GPT对前一段文章的后验预测如此之好。
而对于那些不太著名的文章,NYT指责ChatGPT传播误导的事实。
主要是因为,如果给定的先前句子集在训练数据中只出现一次,则预测的后验文本将不会与训练数据匹配。它会「幻觉」出类似合理的文本。
幻觉之所以会发生,是因为大模型根本不了解事实,而只知道下一个词的分布。
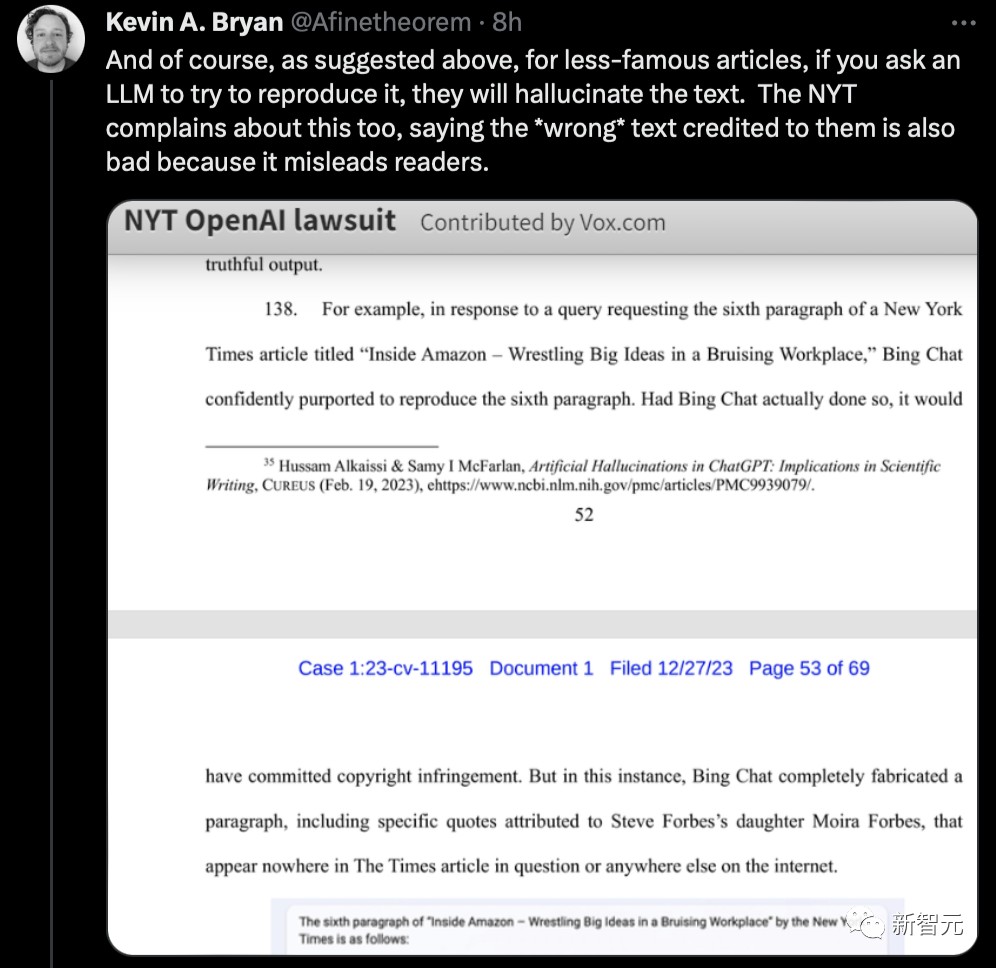
这是一件大事,因为它可能为两个方面建立先例:1. 法院怎样确定新闻内容在训练大语言模型时的价值;2. 对于之前的使用情况,应当支付多少赔偿。
Midjourney吐出「原图」?
不仅仅是OpenAI、微软,就连最强的AI作图神器Midjourney也将在未来面临一大波的起诉。
Midjourney V6升级后惊艳了全网,但同时有人发现,其输出的图片完全和好莱坞等电影剧照毫无差别。
曾为漫威工作的插画家兼电影概念艺术家Reid Southen表示,只需要15分钟,就能找到Midjourney侵犯版权和剽窃的证据。
如下的图片中,可以看出生成的图像与电影原作非常接近,仅在镜头角度或姿势等方面存在细微差别。

他还制作了一段视频,展示了自己使用Midjourney V6进行的剽窃实验。

因为他发表的评论,Southen已经被踢出了Midjourney Discord小组。
据Southen表示,AI软件可以完全复制受版权保护的知识产权,并且可以创作无限的衍生品。
艺术家将在同一市场上与自己的作品竞争。当网上50%的漫威作品最终都是人工智能的山寨品时,品牌形象问题和消费者的困惑又将如何解决?
《蒙娜丽莎》这样的经典艺术品,只提供两个字的提示,就能完全复刻原图。
而且在这种情况下,这种行为并不会在法律上被判为“剽窃”,因为《蒙娜丽莎》的年代久远,已经属于公有版权。

2019年由托德·菲利普斯执导的电影「小丑」中的画面,也被Midjourney V6「拿来即用」。

这两张图如此相似,不得不让人怀疑,这似乎就是在训练数据中微调之后的版本。
而它们的不同之处,在于灯光和色彩。

矩阵中的基努,也和原片几乎一毛一样。
Midjourney V6甚至可以复制任何动画风格。

小黄人、瑞克和莫迪、巴斯光年等等,完全逼真全现。

为了最大限度地提高性能,新模型可能会在相同的数据上反复强化训练,导致输出结果与训练数据几乎完全相同。
这就是所谓的「过拟合」,此前研究表明这种情况可能会发生。ChatGPT也会出现文本过拟合的迹象。
全新的V6模型很可能是一枚重磅炸弹。目前,Midjourney已经卷入了至少一起诉讼。
以后网上这些画面究竟是原动画还是AI生成,恐怕没人能分得清了。

Prompt: scene from the simpsons [character] --ar 16:9 --style raw --v 6

Prompt: scene from finding nemo [character] --ar 16:9 --style raw --v 6

Prompt: scene from dragonball [character] --ar 16:9 --style raw --v 6

Prompt: scene from rick and morty --ar 16:9 --style raw --v 6

Prompt: scene from frozen --ar 16:9 --style raw --v 6
参考资料:
https://www.nytimes.com/2023/12/27/business/media/new-york-times-open-ai-microsoft-lawsuit.html
https://the-decoder.com/midjourneys-v6-model-draws-close-to-copyright-infringement-with-movie-scene-images/
https://twitter.com/CeciliaZin/status/1740109462319644905
https://twitter.com/maxaltl/status/1740116230114312264
本文(含图片)为合作媒体授权创业邦转载,不代表创业邦立场,转载请联系原作者。如有任何疑问,请联系editor@cyzone.cn。







